リッカート尺度項目例
(性格検査)
1 人のあつかいがうまい はい ? いいえ
2 たびたび考えこむくせがある はい ? いいえ
(価値観)
1 特定の生き方にはまらず、柔軟な生き方をしたい。
1.賛成 2.やや賛成 3.どちらでもない 4.やや反対 5.反対
2 自分の人生の中では、多元主義を貫きたい
1.大いに賛成 2.賛成 3.どちらでもない 4.反対 5.大いに反対
SD尺度項目例
こぶとりじいさん
非 か どと どい どと か 非
常 な ちい ちえ ちい な 常
に り らう らな らう り に
かと とい かと
も
すきな +----+----+----+----+----+----+ きらいな
小さい +----+----+----+----+----+----+ 大きい
強い +----+----+----+----+----+----+ 弱い
非 か どと どい どと か 非
常 な ちい ちえ ちい な 常
に り らう らな らう り に
かと とい かと
も
すきな 1 ----2 ----3 ----4 ----5 ----6 ----7 きらいな
小さい 1 ----2 ----3 ----4 ----5 ----6 ----7 大きい
強い 1 ----2 ----3 ----4 ----5 ----6 ----7 弱い
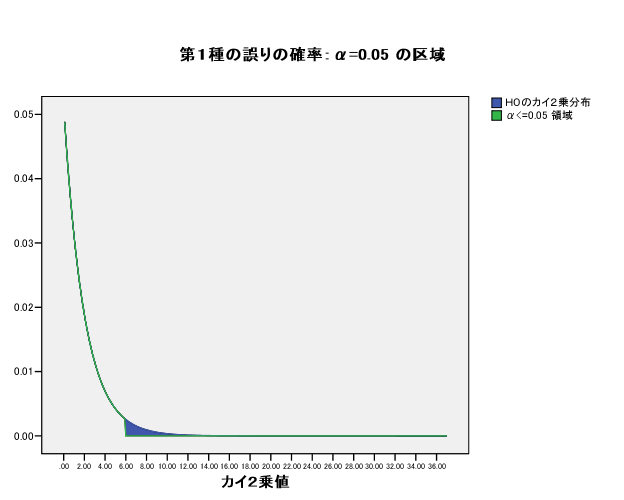
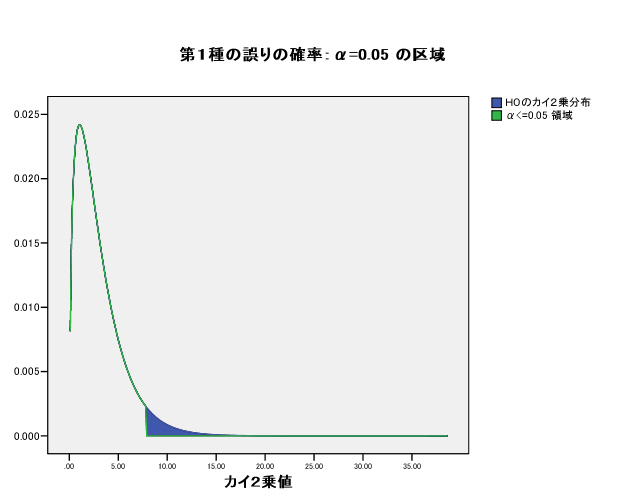
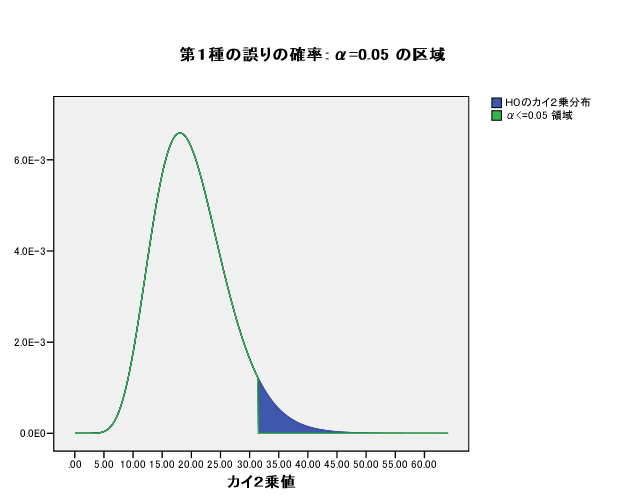
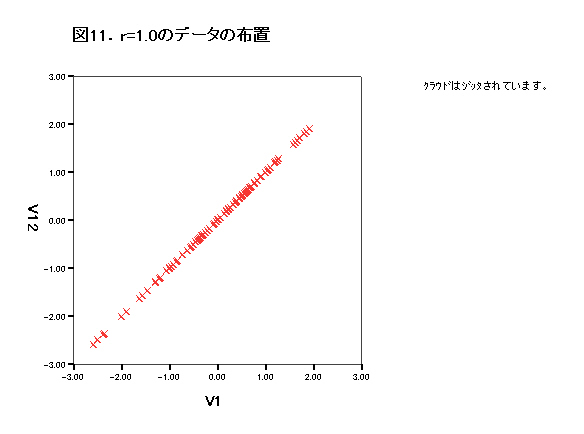
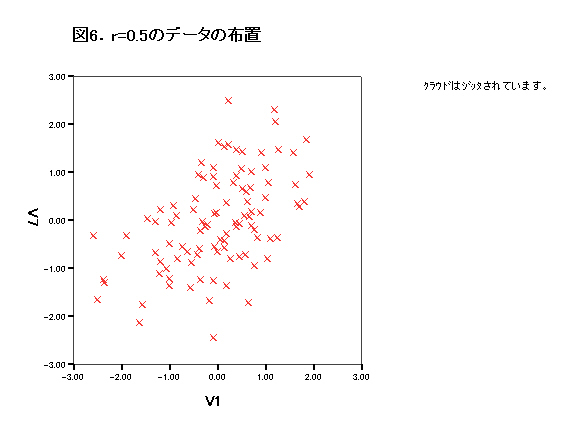
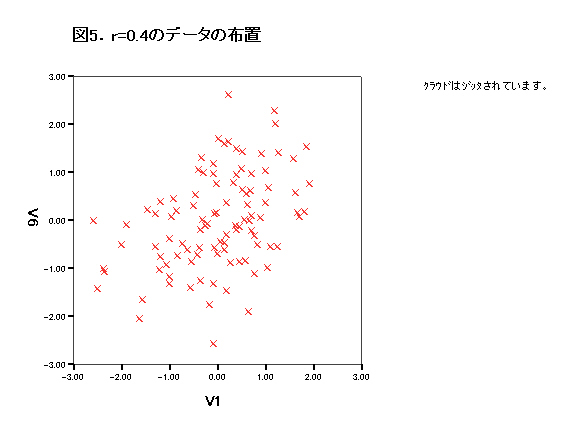
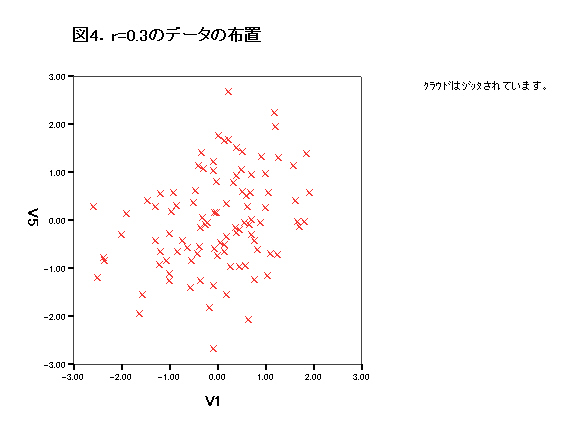
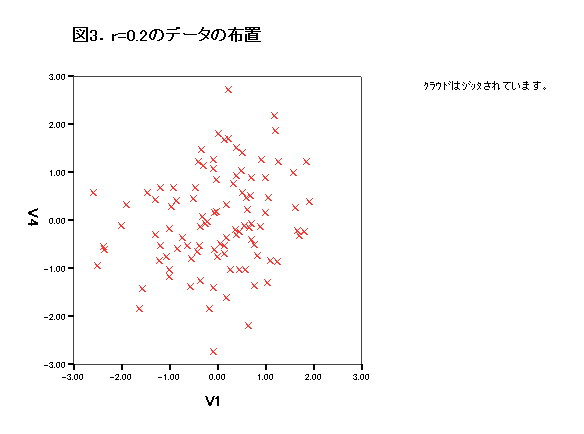
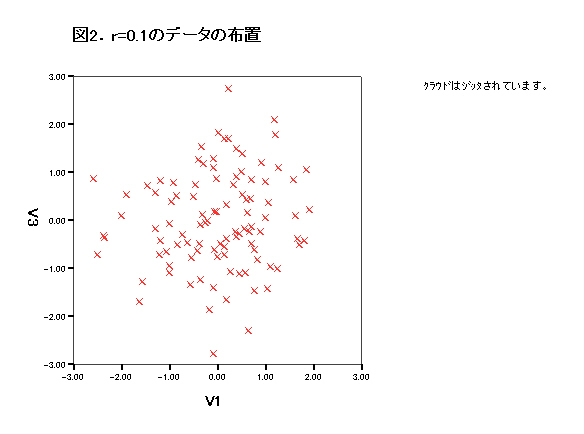
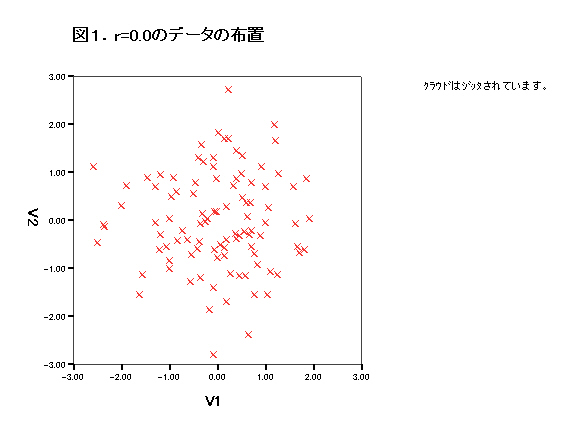
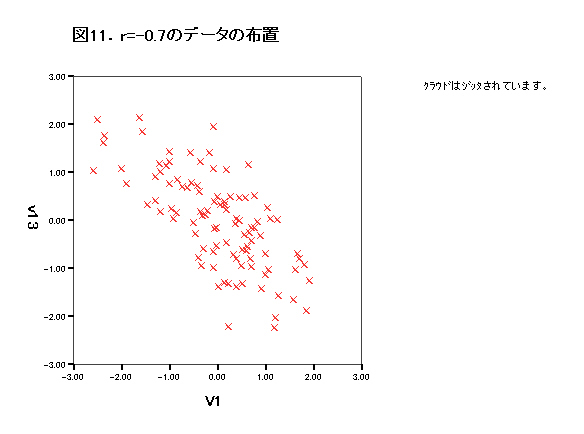
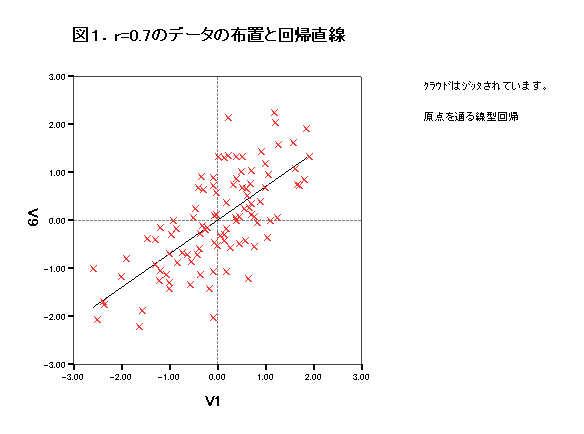
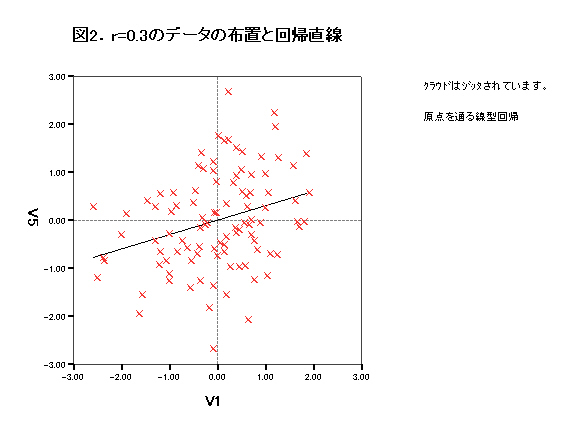
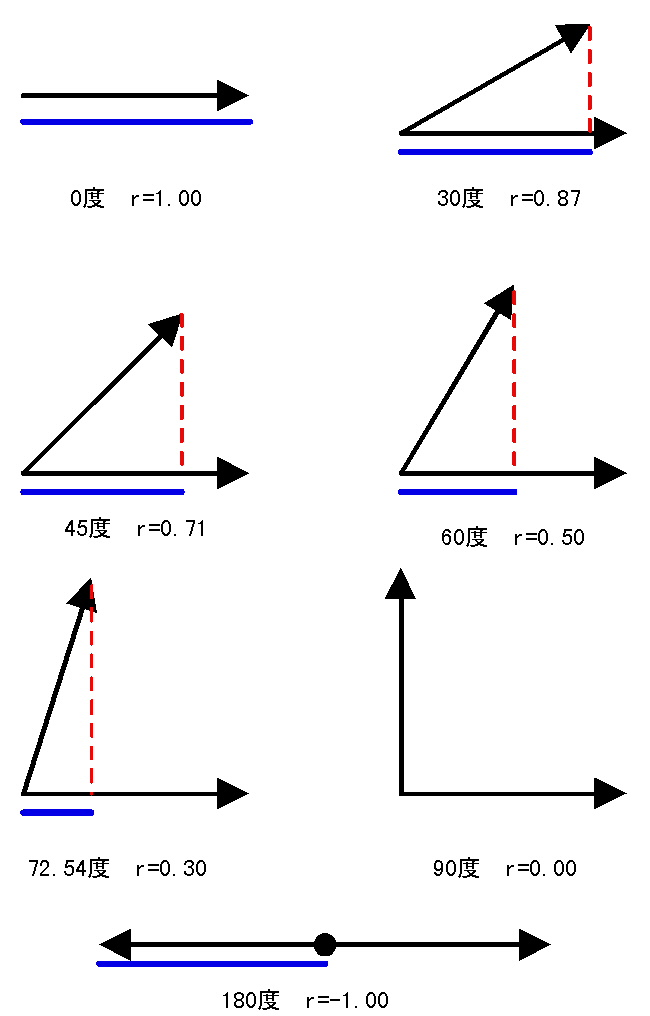
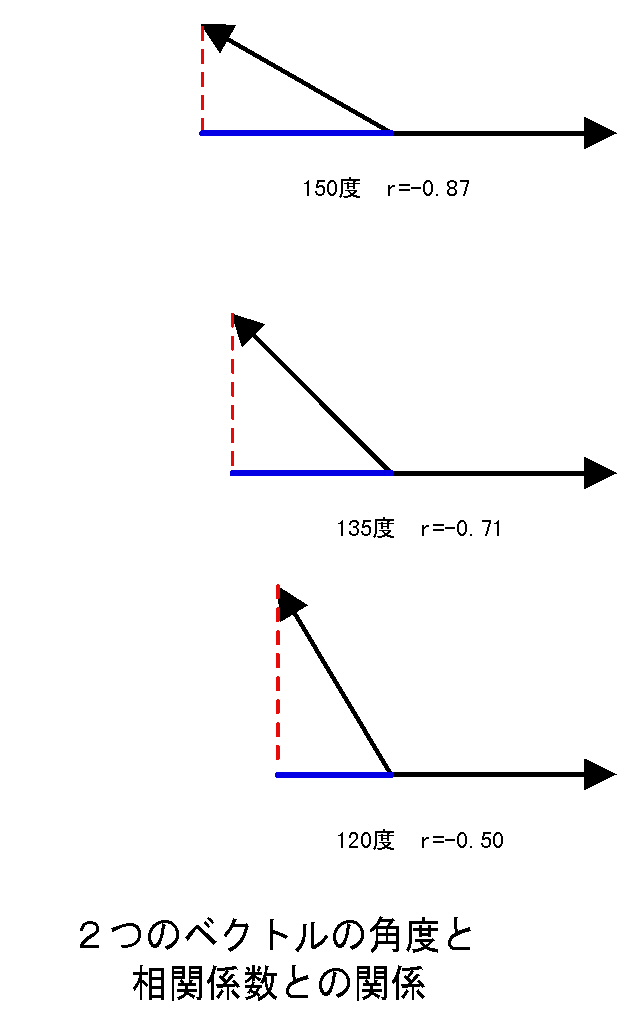
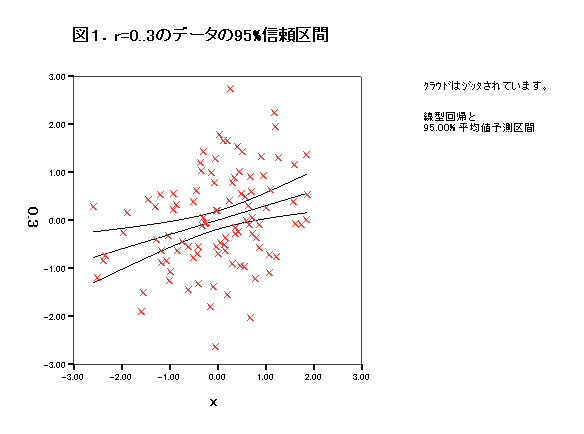
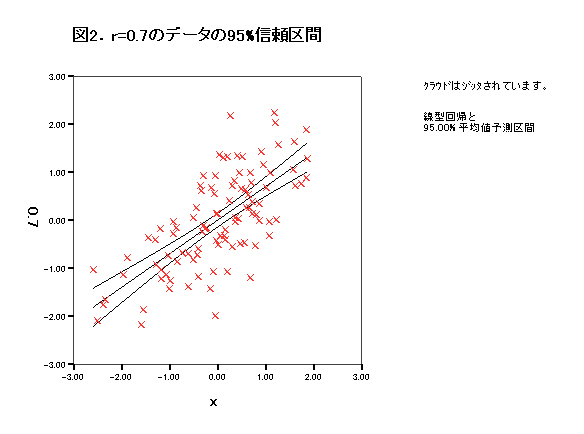
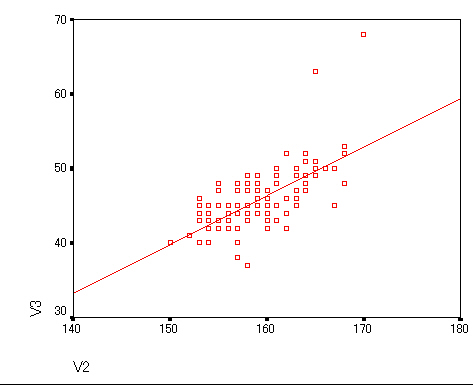
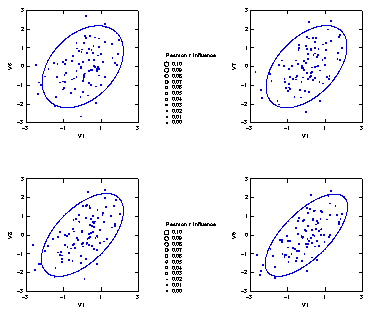
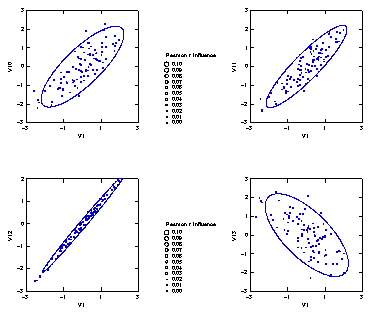
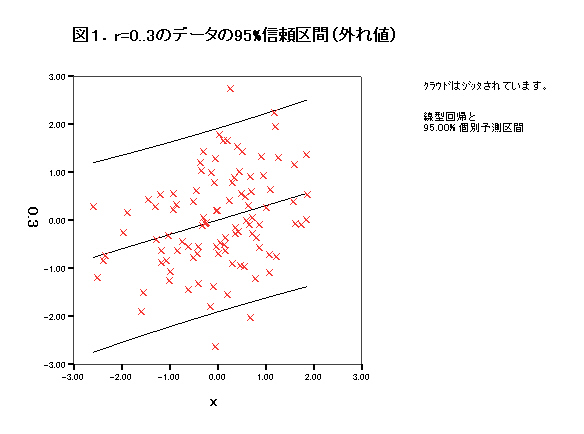
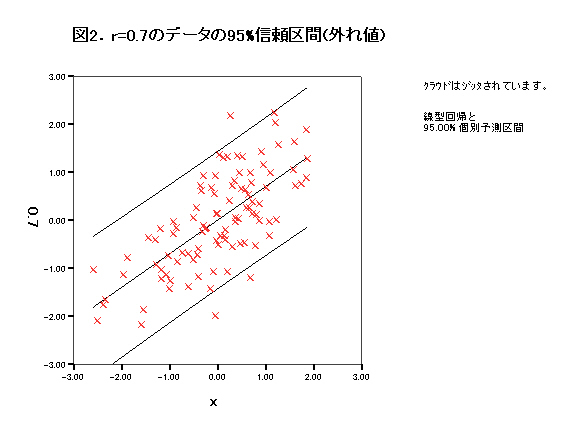
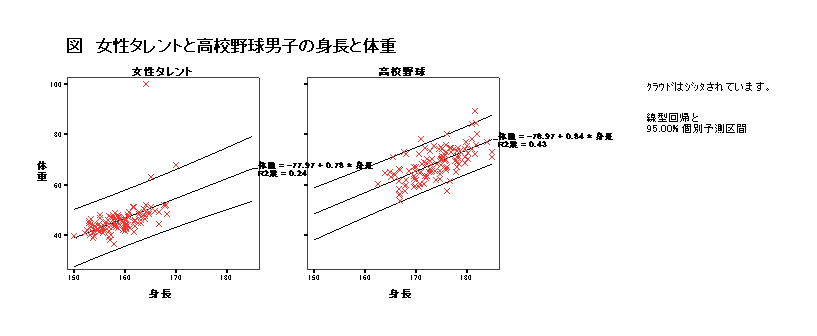
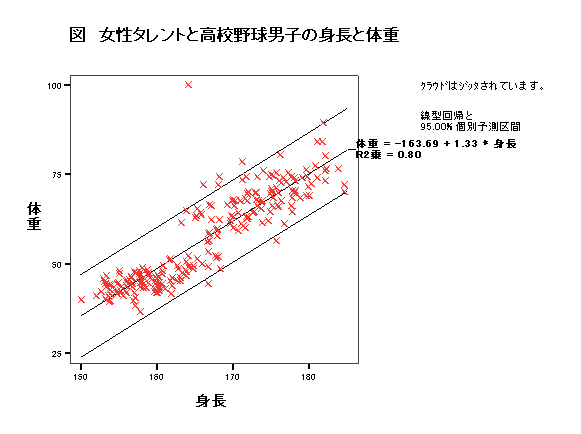
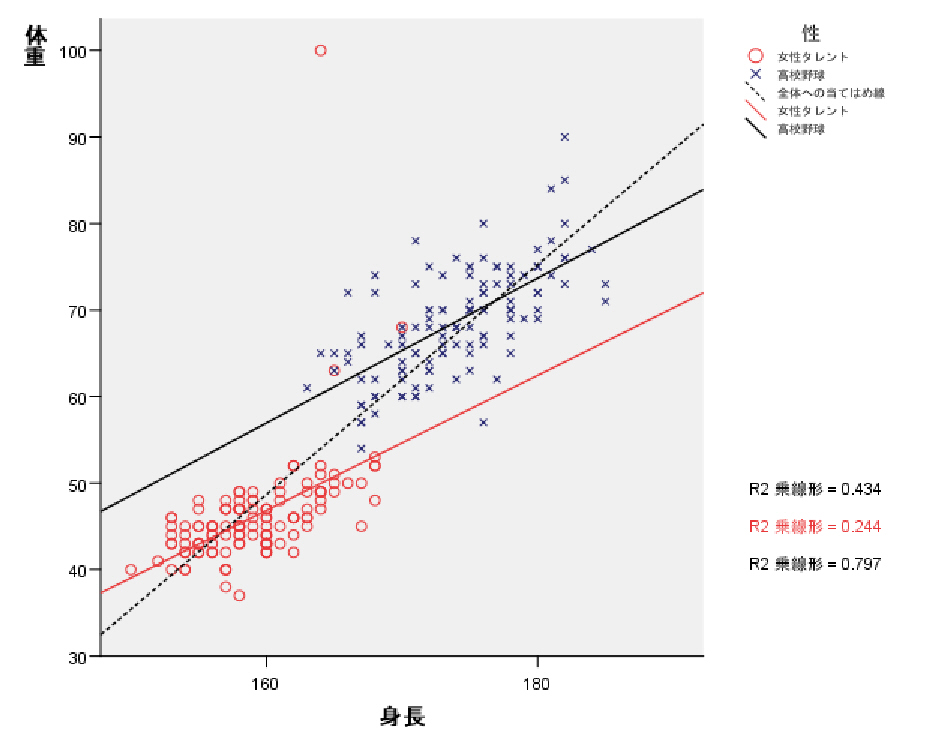
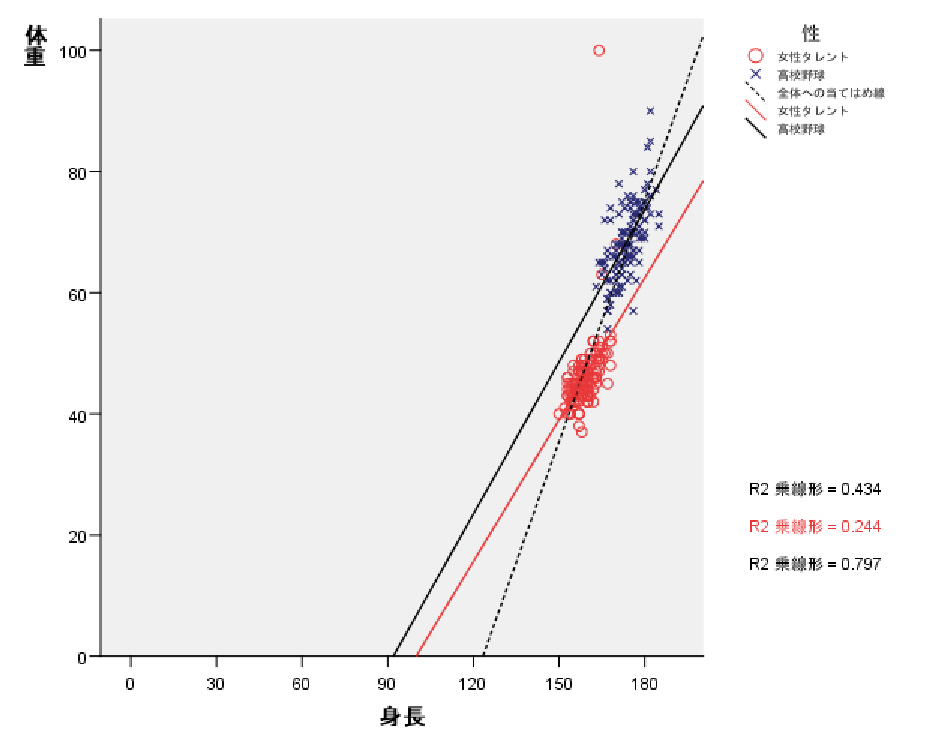
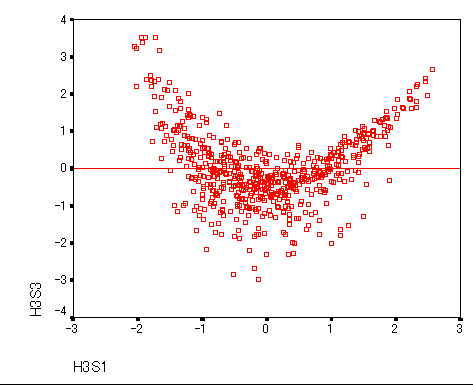
集中楕円が重要であるが、spssでは今のところ出力できない。
→systat 90%集中楕円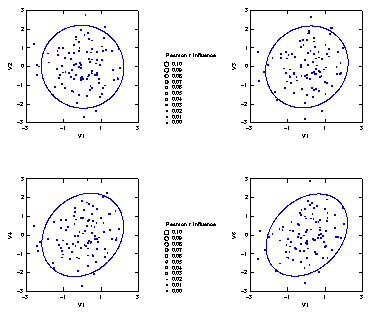
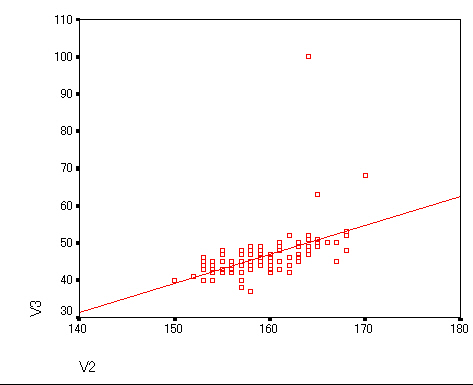
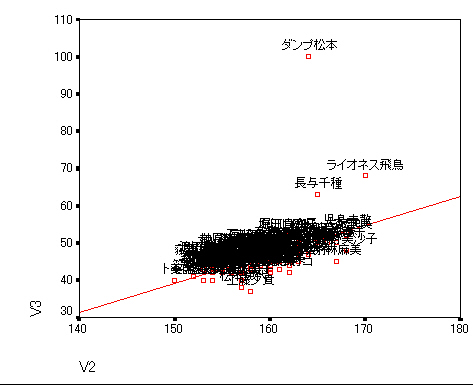
|
|
|
|
|
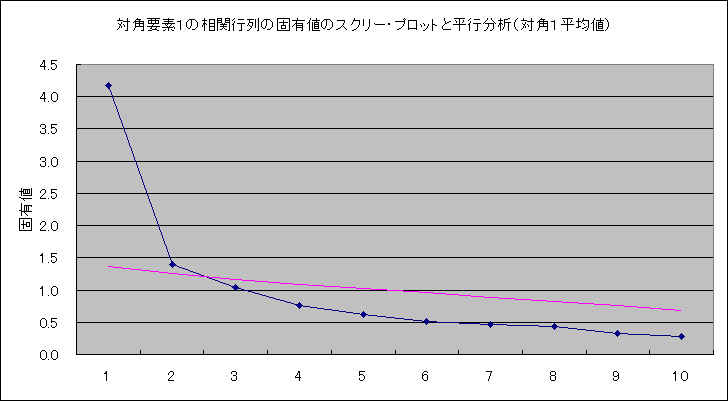
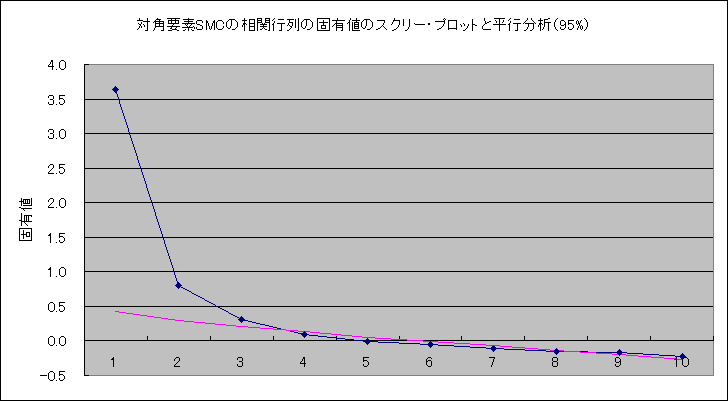
| 因子 | ||||
| 1 | 2 | 3 | 4 | |
| 1(2)この製品に関して豊富な知識をもっている。 | 0.869 | 0.073 | 0.142 | 0.027 |
| 1(4)友人が購入するとき,アドバイスできる知識のある製品である。 | 0.734 | 0.053 | 0.216 | -0.054 |
| 1(14)いろいろなメーカーの品質や機能の違いがわかる製品である。 | 0.671 | 0.054 | 0.381 | 0.027 |
| 1(1)愛着のわく製品である。 | 0.632 | 0.471 | 0.162 | 0.106 |
| 1(9)いろいろなメーカーの製品を比較したことがある。 | 0.607 | 0.062 | 0.303 | -0.174 |
| 1(13)いりいろなメーカー名やブランド名を知っている製品である。 | 0.453 | 0.198 | 0.445 | -0.395 |
| 1(11)魅力を感じる製品である。 | -0.088 | 0.858 | 0.086 | 0.304 |
| 1(5)私にとって関心のある製品である。 | 0.216 | 0.620 | 0.041 | 0.288 |
| 1(12)商品情報を集めたい製品である。 | 0.039 | 0.618 | 0.137 | 0.148 |
| 1(6)私の生活に役立つ製品である。 | 0.102 | 0.613 | 0.042 | -0.155 |
| 1(3)使用するのが楽しい製品である。 | 0.491 | 0.590 | 0.009 | -0.118 |
| 1(15)この製品を次に買うとすれば,購入したい特定のブランドがある。 | 0.221 | -0.102 | 0.782 | 0.102 |
| 1(8)買いに行った店に決めているブランドがなければ他の店に行っても同じものを手に入れたい製品である。 | 0.200 | 0.294 | 0.781 | -0.006 |
| 1(7)この製品の中にはお気に入りのブランドがある。 | 0.353 | 0.134 | 0.652 | 0.014 |
| 1(10)お金があれば買いたい製品である。 | -0.057 | 0.386 | 0.104 | 0.811 |
| "因子抽出法: 重みなし最小二乗法 回転法: Kaiser の正規化を伴わないバリマックス法" | ||||
| a | 7 回の反復で回転が収束しました。 | |||
|
|
| 主成分分析 | 因子分析 | |
| 回転 | 回転をしない | 回転をする |
| 共通性 | 推定しない 数学的に単純.一意 | 推定する 問題があるが,反復推定が当たり前になっているので以前ほど大きな問題ではなくなっている |
| 因子数 | 前もって決定する必要はない.→数学的に単純明解 回転をする場合は主成分数を前もって決めなければならない.その場合は因子分析と同じくその数によって因子が異なってくる. | 前もって因子数を決定する. その数によって因子が異なってくる. |
| モデル | 項目を少ない主成分で説明する. 項目→主成分 分散の最大化 | 因子を反映したものが項目. 因子→項目 潜在因子を想定する |
| 誤差 | 測定誤差のみ | 測定誤差+標本誤差(+誤モデルによる誤差)→独自性 |
| 因子不変性 | なし そのデータを表したものでしかない | あり |
| 因子負荷量 | 大きい | 適正 |
| 因子得点 | 数学的に一意に求めることができる | 前提条件の付け方によって値が異なる |
| 不適解 | なし | おこることがある |
| 等分散性のための Levene の検定 | 2 つの母平均の差の検定 | |||||||||
| F 値 | 有意確率 | t 値 | 自由度 | 有意確率 (両側) | 平均値 の差 | 差の 標準誤差 | 差の 95% 信頼区間 | |||
| 下限 | 上限 | |||||||||
| MALE | 等分散を仮定する。 | 1.849 | 0.175 | 0.309 | 239.000 | 0.758 | 0.186 | 0.603 | -1.001 | 1.373 |
| 等分散を仮定しない。 | 0.302 | 158.905 | 0.763 | 0.186 | 0.617 | -1.032 | 1.404 | |||
| FEMALE | 等分散を仮定する。 | 0.623 | 0.431 | -0.784 | 239.000 | 0.434 | -0.356 | 0.454 | -1.250 | 0.538 |
| 等分散を仮定しない。 | -0.815 | 189.198 | 0.416 | -0.356 | 0.437 | -1.217 | 0.505 | |||
|
男性性の合計点(8〜40)の男子平均点は20.5(S.D.=4.7),女子平均点は20.3(S.D.=4.3)であった。t検定を行ったところt(239)=0.3(p=0.758)となり男女に5%水準において有意差はなかった。女性性の合計点(6〜30)の男子平均点は17.3(S.D.=3.1),女子平均点は17.6(S.D.=3.5)であった。t検定の結果,t(239)=-0.784(p=0.434) となり5%水準において男女の有意差はなかった。 |
| 男性性の男子平均点は20.5(S.D.=4.7),女子平均点は20.3(S.D.=4.3)であった。t検定を行ったところt(239)=0.3(p=0.758)となり男女に5%水準において有意差はなかった。男女によって男性性の平均点には差がない。 |
|
Duncna......有意になりすぎる。あまりにも冒険的 |
| S-N-K.......有意になりすぎる |
| 最小有意差..有意になりやすい |
| Sceffe......有意になりにくい |
| Bonferroni..比較が多いと有意になりにくい |
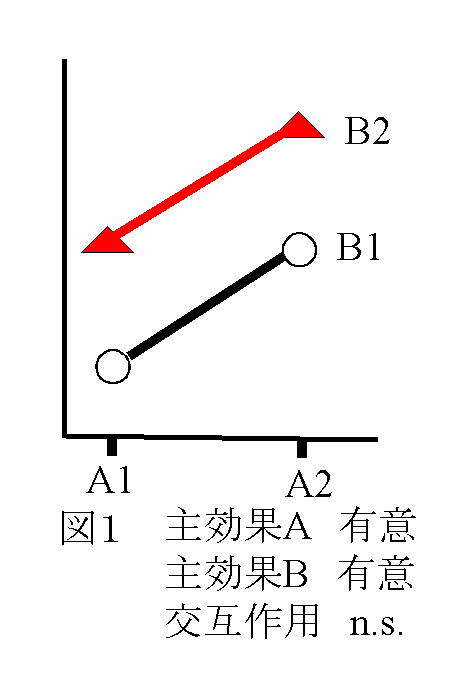
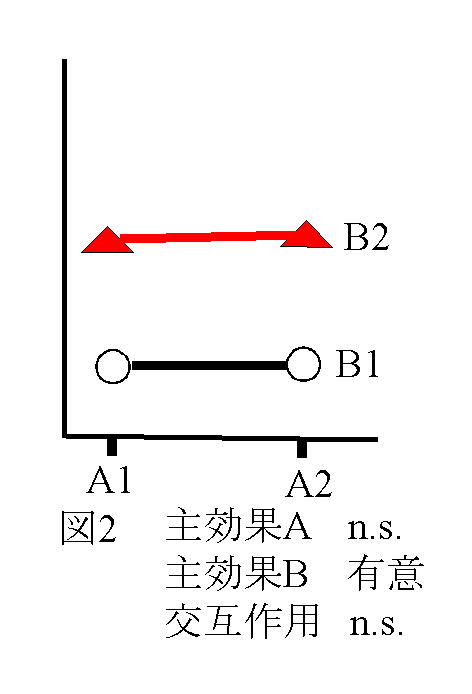
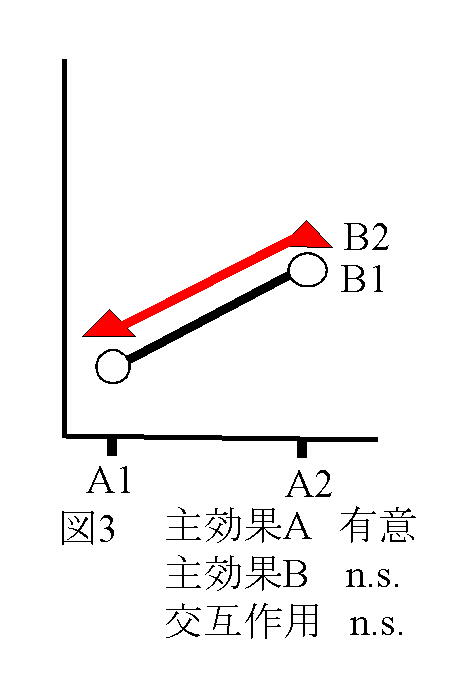
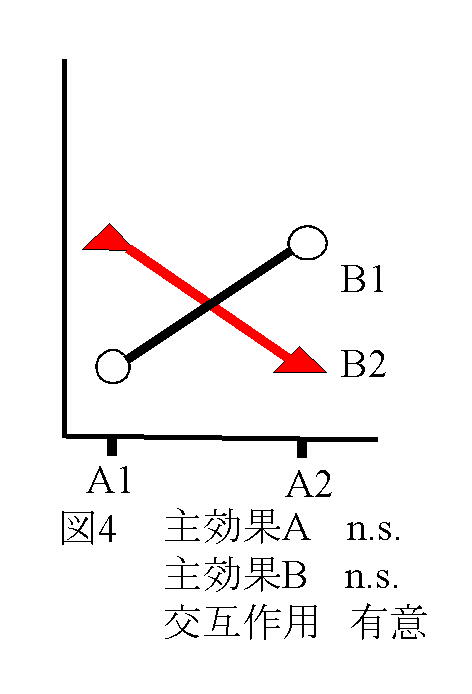
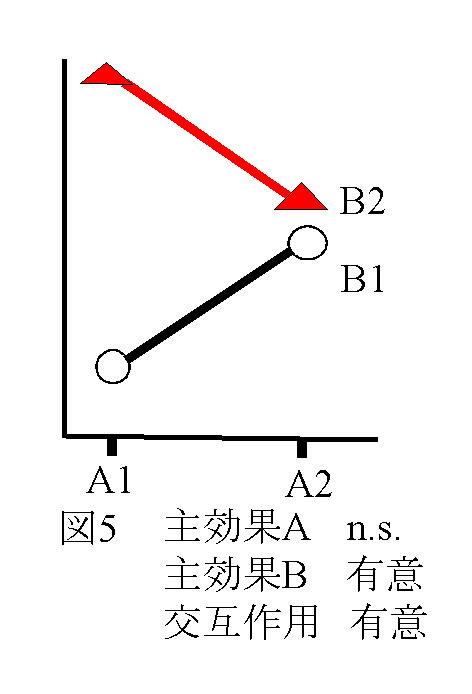
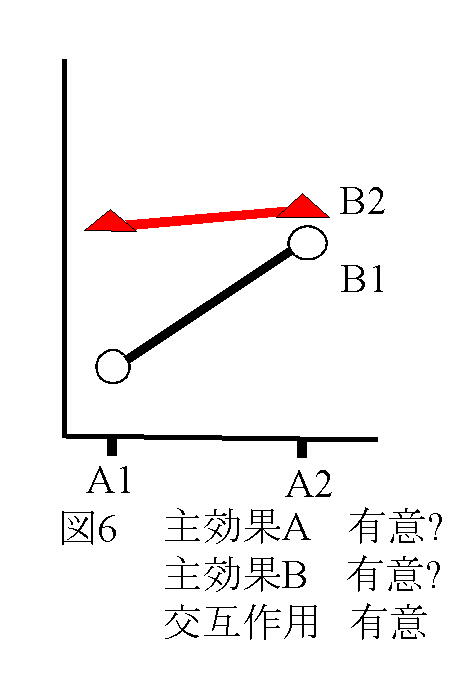
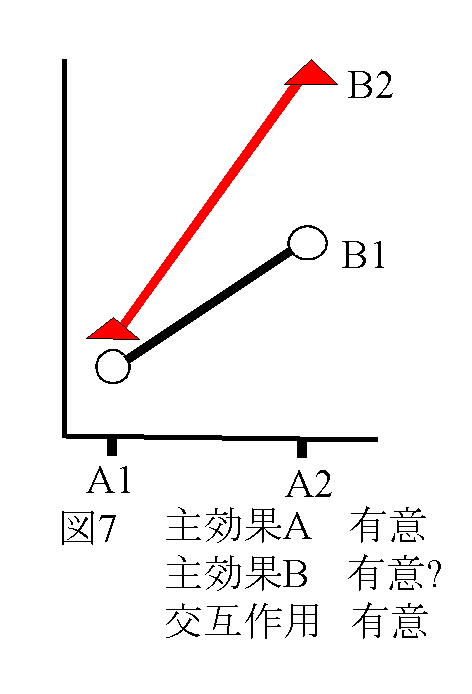
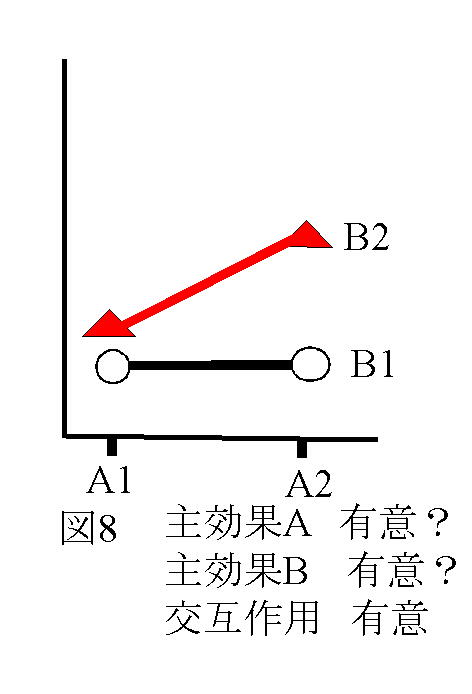
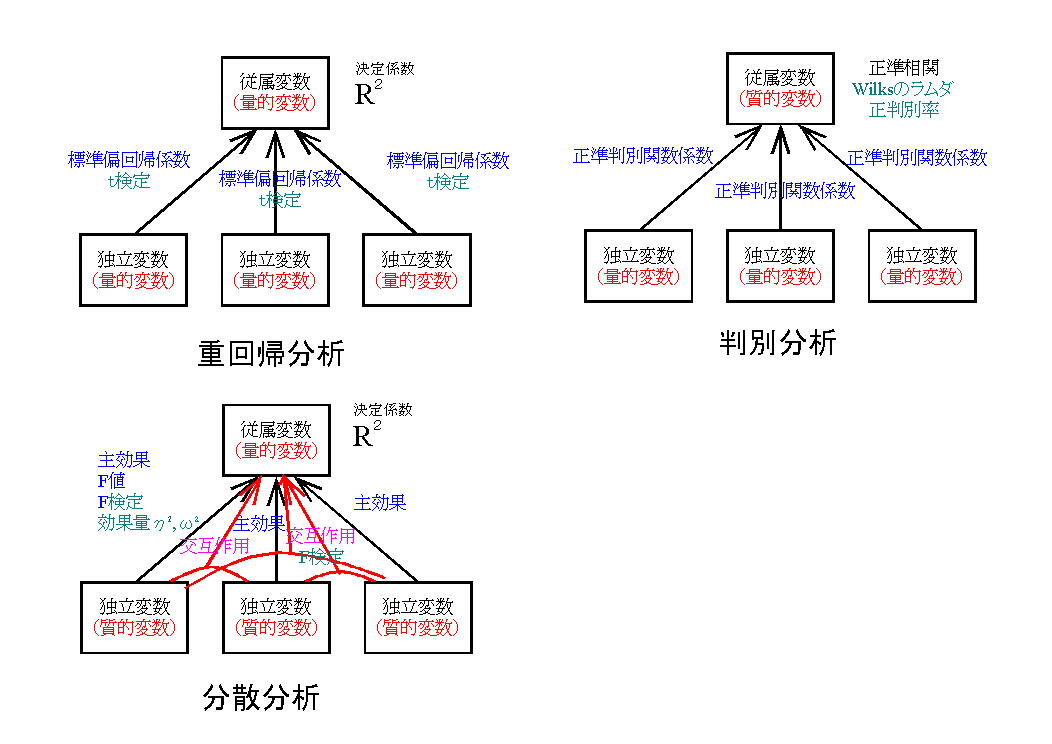
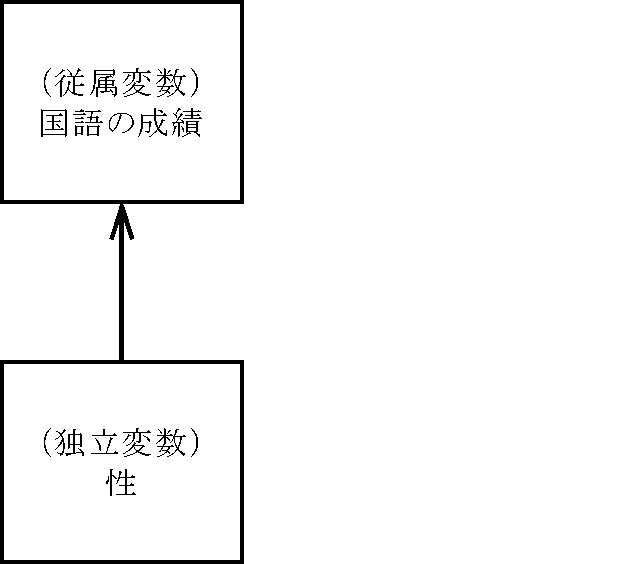
独立変数(予測変数))が与えられたときに従属変数(基準変数)を予測する式をつくることである。その結果、独立変数の値が与えられたとき従属変数を予測することができる。
excel などの表計算ソフトに独立変数のリストと従属変数を求める計算式をセルにいれておき、独立変数をいろいろ変えてみて従属変数の変化を見て意思決定をするのに役立てる。独立変数は現実のデータでもよいし、こうなればどうなるという試行錯誤でもよい。