後半部において、有意差、クロス表、カイ2乗検定、調整済み残差、効果量、高次のクロス集計表および探索(catdap02) について簡単に説明している。
これらをすべて使っている人はほとんどいないでしょう。是非統計処理と調査データの処理に使ってみてください。
SPSS ときど記(217) 2005/10/14
IGPAPH 散布図のSYNTAX
インターラクティブグラフは通常のグラフよりも便利になっている。散布図も回帰直線や95%信頼区間の曲線を手軽に引けるようになっている。同様のグラフをたくさん描く場合はマウスでいちいち操作するのは大儀である。そこでシンタックスを使うことになる。ところがこのシンタックスがよくわからない。そこで例を使って説明しよう。残念ながらすべての操作をシンタックスで記述することはできない。例えばマーカーの形などは指定できないのでマウス操作をするしかない。次のシンタックスを使って描いたのが図1である。 DATA(CORR07.SAV)
IGRAPH /VIEWNAME='図1'/X1 = VAR(V1) TYPE = SCALE(min=-3 max=3) /Y = VAR(V9) TYPE = SCALE(min=-3 max=3)
/COORDINATE = VERTICAL
/TITLE='図1.r=0.7のデータの布置'
/X1LENGTH=3.0 /YLENGTH=3.0
/CHARTLOOK='NONE'
/SCATTER COINCIDENT = jitter(2)
/FITLINE METHOD=REGRESSION LINEAR INTERVAL(95)=MEAN LINE=TOTAL.
.
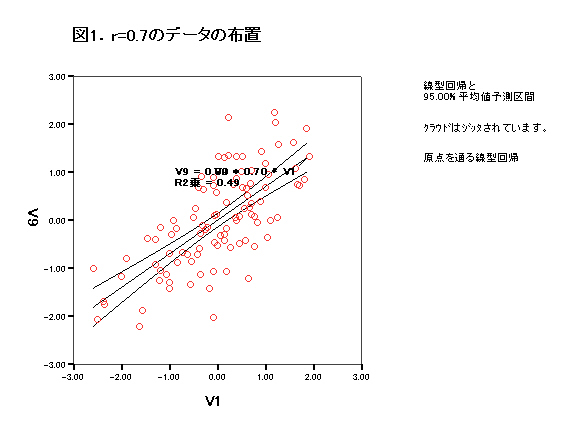
一つ一つ説明使用。
IGRAPH /VIEWNAME='図1'
これは出力窓の左側のアウトラインのグラフ部分にタイトルを付ける。出力を探すのに便利である。
/X1 = VAR(V1) TYPE = SCALE(min=-3 max=3) /Y = VAR(V9) TYPE = SCALE(min=-3 max=3)
X軸,Y軸の変数名と軸の最小値(-3)と最大値(3)を規定している。最小値,最大値の指定は図を統一するために重要である。
/COORDINATE = VERTICAL
/TITLE='図1.r=0.7のデータの布置'
図のタイトルを付ける。出力を見るとわかるように科学論文の方式とは違い上にタイトルが付いている。下にしなければならない。
/X1LENGTH=3.0 /YLENGTH=3.0
図の大きさを定義する。
/CHARTLOOK='NONE'
これは,あらかじめ図の属性を決めたファイルを使う場合はそのファイルを指定する。
/SCATTER COINCIDENT = jitter(2)
SCATTER は散布図。JITTERはプロットの際,同一点を占める点は少しずらして表示する。(2)はずらす程度でこれは2%。ずらさない場合はNONE
/FITLINE METHOD=REGRESSION LINEAR INTERVAL(95)=MEAN LINE=TOTAL.
REGRESSION LINEARは回帰直線を引く。原点を通る回帰直線はORIGINAL LINEAR。描かない場合はNONE。そのほかにLLRがあるがこれを使いたい場合はMANUALを読んでください。
平均値の信頼区間を描くのがINTERVAL(95)=MEAN。外れ値を知るための信頼区間を描くにはINTERVAL(95)=INDIVIDUAL
マウスを使った処理。
シンタックスを知るには,メニューの指定後,貼り付けを使うか,そのまま走らせて,出力の記録を調べるといい。
SPSS ときど記(213) 2005/ 4/25
SPSS SPSS14
SPSS14がリリースされた。まだ英語版の予約受付です。バージョンアップの内容は次のところ。
http://www.spss.com/spss/brochures.htm
SPSS ときど記(216) 2005/10/ 4
SPSS SPSS14日本語版リリース案内来る
PSS14日本語版リリース案内が来た。 http://www.spss.co.jp/product/spss/spss14.html リリースは12月26日予定。
教育用のバージョンアップ費はだいぶ軽くなった。今回あらてめてちゃんと見るとbase は33,600円 で改訂していないオプションは1680円(conjointだけ1050円)、機能増になっているオプションが8,400円となっている。
ver 4のころにSPSSにつけた注文が漸く実現したようである。変わってないオプションのバージョンアップ代をだすのはばからしい。当時は数万円していた。そのため何回か後にtable などは使うことがなくなっていたので切り捨てた。
おっと、tableの新機能に「多重回答変数の有意性検定」をするらしい。どんなことをするのだろう。
SPSS ときど記(215) 2005/ 9/28
クロス表 catdap マクロ・スクリプト改訂版
クロス表分析の強力なツールであるcatdap02のマクロとスクリプトを改訂した。(1)3つ説明変数を使ったときのバグを修正
(2)クロス表出力の追加
(3)説明変数を1つにするオプションの追加
(4)スクリプトの場合、ファイルへの保存は既存のファイルを使っているときはそのファイルを呼び出すことにする。マクロの場合は常にc_temp_.sav になる。スクリプトの場合ファイル名がついていない場合はc_temp_.sav になる。
出力例はここ。 マクロ スクリプト
SPSS ときど記(214) 2005/ 9/15
行列言語 エラーメッセージ(DO IF... END IF)
久しぶりに行列言語を使ったらDEBUG でまたまた苦労した。エラーメッセージのでるところがよくわからないのである。MATRIX.
.....(すでにちゃんと動いている部分)
.....
DO IF ...(1)
..
DO IF.....(2)
....
END IF.....(3)
DO IF......(4)
......
END IF.....(5)
......
END IF.....(6)
......
DO IF.......(7)
......
END IF......(8)
END IF......(9)
というようにDO IF やLOOP がたくさんでてくる複雑なプログラムになった。
次のエラーメッセージが(1)の前にでてくる。
>Error # 12313 in column 256. Text: (End of Command)
>ELSE、ELSE IF、またはEND IFのネスト構造が不適切です。
>This command not executed.
エラーメッセージのでる場所はprint を挿入して確かめた。そうすると、(1)の前に間違いがあると思われるがない。また、(1)のdo if 文をコメントアウトすると、同じところで文句をいいさらに(9)のところで文句をいってくる。いろいろ調べて、(6)が余分であることがわかった。
こんなとき普通(6)のあとに文句を言うのではないか。という疑問をもった。エラーメッセージはそのエラーの生じたところではなく、その前でもつけてくることがわかった。
SPSS ときど記(213) 2005/ 4/25
SPSS SPSS14
SPSS14がリリースされた。まだ英語版の予約受付です。バージョンアップの内容は次のところ。
http://www.spss.com/spss/brochures.htm
SPSS ときど記(212) 2005/ 4/25
DATA MATRIX DATA とNの指定
MATRIX DATA にケース数を複数指定できる。変則指定の仕方だが、次の例からSPSSの処理の仕方が分かる。
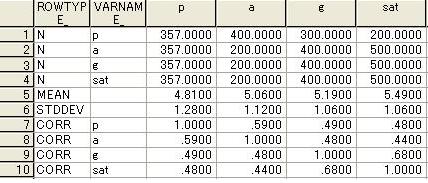
次のシンタックスで処理する。因子分析を行う。
FACTOR MATRIX=IN(COR=*)/ANALYSIS=A TO SAT/
PRINT DEFAULT UNIVARIATE.
警告
| ケース数 (N's) の行列が存在するため、欠損データはペアごとに処理されます。 |
| 記述統計量 | ||||
| 平均値 | 標準偏差 | 分析 N | 欠損値 N | |
| a | 5.060000 | 1.1200000 | 400 | 100 |
| g | 5.190000 | 1.0600000 | 300 | 200 |
| sat | 5.490000 | 1.0600000 | 200 | 300 |
1行だけのNを指定する(例えばこのデータのNの1行目)と
警告
| ケース数 (N's) の入力行内の値が同じでありません。最初の値が、ケースの数として使用されます。 |
という警告がでて、処理がされない。警告と一致していない点も気になる。
しかも、Nを変数ごとに使用する意味がどの程度あるのかは不明である。
中途半端な数Nを指定すると
警告
|
ケース数 (N's) の行列は正方行列ではありません。 このコマンドは実行されません。 |
なお、標準的指定法は
SPSS ときど記(208) 2005/ 2/21 DATA matrix data と因子分析,重回帰分析,AMOS
にある。
SPSS ときど記(211) 2005/ 4/22
重回帰 多重共線性と抑制変数
重回帰分析において多重共線性は気をつけなければいけないことである。小塩真司『SPSSとAmosによる心理・調査データ解析』東京書籍 (2004)
の重回帰分析の章でちょっと気づいたことが.
(1)なんで多重共線性の指標を使わないのだろう
(2)この演習(p.103)で使われている服部・海保(1996)のデータは実は抑制変数の例でもある.
(3)服部・海保(1996)での多重共線性チェックのbootstrapの使用
(1)小塩では多重共線性について説明しながらSPSSの多重共線性の指標を出力するオプションを教えていない.そしてややこしいことに抑制変数の説明に多重共線性が顔をだす.多重共線性の問題の本質は解が不安定なことにある.そういう意味で,(3)にあるようにbootstrap で不安定性を示すのが一つの方向である.やはり指標を使う方が簡単であろう。
spssの重回帰では
回帰分析 分析→回帰→線形
統計→共線性の診断
によってVIFと許容度を出力します。
で、服部さんの多重共線性の例データ(Q & A 心理データ解析 P140表6-4)を処理するとVIFの最大値はx2の7.3です。一般に言われる VIF>10 には届いていません。許容度=1/VIFです。VIFを使うことが多いのでVIFを指標とします。VIF>10なら許容度<0.1となります。
係数(a)
| モデル | 非標準化係数 | 標準化係数 | t | 有意確率 | 共線性の統計量 | ||||
| B | 標準誤差 | ベータ | 許容度 | VIF | |||||
| 1 | (定数) | .970 | 1.090 | .890 | .388 | ||||
| x1 | .454 | .371 | .444 | 1.225 | .240 | .161 | 6.199 | ||
| x2 | .257 | .262 | .385 | .978 | .343 | .137 | 7.305 | ||
| x3 | .286 | .369 | .275 | .776 | .450 | .169 | 5.904 | ||
| x4 | -.187 | .180 | -.296 | -1.043 | .313 | .263 | 3.798 | ||
| a | 従属変数: y | ||||||||
固有値の条件指標は24.431, 21.019の2つが15以上の要注意にひっかかります。全くダメな30には届いていません。spssの条件指標の用語ヘルプを参照のこと。
共線性の診断
| モデル | 次元 | 固有値 | 条件指標 | 分散の比率 | ||||
| (定数) | x1 | x2 | x3 | x4 | ||||
| 1 | 1 | 4.835 | 1.000 | .00 | .00 | .00 | .00 | .00 |
| 2 | .116 | 6.454 | .22 | .00 | .02 | .00 | .13 | |
| 3 | .029 | 12.821 | .16 | .02 | .20 | .03 | .85 | |
| 4 | .011 | 21.019 | .62 | .25 | .77 | .24 | .01 | |
| 5 | .008 | 24.431 | .00 | .73 | .00 | .73 | .01 | |
| a | 従属変数: y | |||||||
固有値の条件指標から次元4と次元5に問題があり、それぞれ、変数x1,x2,x3 と変数x1,x3が多重共線性の問題を起こしている。こんれらのうち2変数を削除すればとりあえず多重共線性による推定値の不安定さは回避できるが、その変数が重要変数である場合は問題が残る。x4を削除しても多重共線性は残る。
VIFは通常10以上を基準としているようですが、Fox(1997)はきちんと書いてませんが、 sqrt(vif)>2 で要チェックと考えているようです。そうするとVIF>4で要チェックの水準にあります。この水準だとだいたい重相関係数が0.9以上になるということです。
Cohenらでも10の基準は高すぎると指摘して、p424 註16にVIF 6とか7, conditional index 15とか20という場合があることを言っている。
同時に行動科学では10以上になることはまずないという指摘もあるので、論理的ミスをしないかぎりあまり心配することないことかもしれない。
で、心理学の2人がなぜ多重共線性の指標に言及しないのかというのが疑問です。小塩さんのはオプションを最低限しかのせないという考えからか。服部さんのはページ数の制限からかなり削ったようです。
でも多重共線性に注意しろというなら指標は重要だと思う。
FoxによるとVIF<10でも、このような中程度に多重共線性のある場合には解の不安定化が生じ、さらにこのほうがRidge回帰や主成分回帰では乗り越えられないのでやっかいだそうです。
服部・海保で載せている抑制変数の体型不満度データの例(p129)はきれいに決まっています。多重共線性と抑制変数が別物だと理解できます。解釈もわかりやすくできる好例です。このデータは小塩(2004)でも使われていて、データファイルに収められてます。演習問題\第5章演習.savです。これを分析すれば、VIFが2以下に収まっていることがわかります。
どの変数の間に多重共線性があるかは条件指標が大きい >15 に対応する固有ベクトルを見ます。固有ベクトルの絶対値がある程度以上の大きさの変数の間に多重共線性が起こってます。多重共線性が起こっている場合の回避策の一つは、多重共線性が起こっている変数を削除することです。2主成分において多重共線性が起こっている場合は2変数削除することになります。
なお、spssでのbootstrapの方法は
SPSS ときど記(185) 2004/ 8/11 OMS ブートスラップのマクロ修正版
にある。
文献
Cohen, H., Cohen, O., West, S. G. and Aiken, L. S. (2003) Applied multiple regression/ correlation analysis for the behavioral scineces. 3rd eds. LEA,
Fox,J.(1997) Applied regression analysis, linear models,l and related methods. Sage.
服部環・海保博之 (1996) Q & R 心理データ解析 福村出版
小塩真司(2004) SPSSとAmosによる心理・調査データ解析 東京書籍
ps.2006/1/18
小塩さんの本が5刷(2005/12/25)からVIFも取り入れた。解説も少し変えた部分がある。これはいいことである。
だが、p97の一番下の表の数値が違っている。元の刷ではあってるのに(^^;。いろんなことが起こるから本は大変である。
編集者から次の刷で直すという連絡を頂いた。6刷が正しいのに戻る。