(Homals で分析するときは現在(遅くとも17版)はsyntax で書くことになる。→メニューでする場合は多重応答分析) spss
分析→データの分解→最適尺度法→最適尺度水準「すべての変数が多重名義」,変数グループの数「単一グループ」チェック→定義→変数指定と範囲の定義をする
a1(1,3),a2(1,4),a3(1,2),a4(1,2),a5(1,3)
→オプション指定→続行→OK
数量化3類テストデータ 駒澤勉『数量化理論とデータ処理』朝倉書店 1982
homals 出力
softdrink2.sav (1,2 data)
homals 出力
softdrink.sav (1,0 data)
Hoffman,D.L., and Franke,G.R.(1986) Correspondence analysis:Graphical representation of categorical data in marketing research, Journal of Marketing Research,23(August),213-27.の「ソフトドリンクのこの1週間の消費」です。
Green, P.E., Carmone, F.J. Jr., and Smith, S.M. (1989). Multidimensinal scaling: concepts and applicatins. Allyon and Bacon. にはソフトドリンクのその他のデータの取り方(ex. 類似度,SD法など)をいろいろやってます。
[分析]→ 次元縮小→ [最適尺度法]
[すべての変数が多重名義] をチェック→ [単一グループ] をチェック→ [定義]
→分析変数指定
→オプションを適当に指定する。
homals と同様の分析をする。
数量化3類スクリプトを使用する。
スクリプトをダウンロードし,Hドライブに hayashi3.sbsとして保存する。
spss
ユーティリティ→スクリプト実行→ファイル指定→スクリプトが走る→変数指定→とりあえずOK
駒澤データの 数量化3類スクリプト出力
softdrink 数量化3類スクリプト出力 駒澤型数量(大きな値になる)
spss
分析→データの分析→>コレスポンデンス分解→行変数指定→定義→列変数指定→定義
対応分析の日本語文献は
大隅昇・L.ルバールほか(1994)『記述的多変量解析法』日科技連
がもっとも詳細。
homals の結果と数量化3類の結果は少し誤差がある。homals は個体数量を規準化しているが,数量化3類ではカテゴリーを規準化しているためと思われる。なお,Gifi の本の結果は数量化3類と同じである。個体数量のほうが大きい行列を扱うことになるので,数量化3類の解のほうが自然に感じられる。
対応分析使用例(商品のグルーピング 下着 携帯電話 野菜調理法 DATA Web 2003 新聞の媒体力 メディアの評価{データ付き} 媒体間のポジショニング ビール等ブランド{pdf ファイル} 折込広告1とダイレクトメール{pdf ファイル} 広告メディアの評価 野菜と産地 消費者金融・銀行系ローン 趣味・娯楽 生涯学習{データ付き})
ビール等ブランドのドトールとスターバックスの対比の分析において明かな馬蹄形がでていることに注意
よくある対応分析はシンタックスを使う。
(1)無糖茶のデータ (mutocha.sav) 日経流通新聞データ
小売り店の無糖茶に対する評価。2001年
もとは%データである。頻度との関係は明白なのでパーセンタイルデータのまま分析する。
下の行をシンタックス(ファイル→新規作成→シンタックス)ででてくる
シンタックスエディタに貼り付けて走らせる(シンタックスエディタの実行→すべて)または(▼印。1行なので,correspondence の行にカーソルを持って行き,▼印をクリック)。
CORRESPONDENCE TABLE=ALL(10,12)/plot=RPOINTS cpoints bipoints .
ALL の後ろの括弧内は,行変数の数(10),列変数の数(12)。
最後は.(ピリオド)がつく。plot は既定値がbipoints(biplot)。行(rpoints),列(cpoints),バイプロット(bipoints)を指定した。別々のほうが見やすい。
出力
この結果は商品が逆U字型になっており,1次元評価と見なすことができる。右が商品力,左が広告力の軸となっっている。第2次元を評価すると,上が店舗系プロモーション,下が顧客プロモーションになっていて,0の近辺が商品力である。項目ではU字型が横を向いている。この場合は第1次元ではなく第2次元が意味があると考えることができる。難しい結果だ。なお,新聞CMが店舗プロモーションの方向によっているのが注目される。
行,列を一緒にプロットするとみにくいので別の図にする。
CORRESPONDENCE TABLE=ALL(10,12) /plot=RPOINTS CPOINTS.
(2)茶飲料データ(cha.sav) 日経流通新聞データ
小売り店の無糖茶に対する評価。2001年
もとは%データである。頻度との関係は明白なのでパーセンタイルデータのまま分析する。
CORRESPONDENCE TABLE=ALL(20,7) /plot=RPOINTS CPOINTS.
出力
第1次元は「CMよい」と他の項目に分かれる。第2次元が「経験」「人気」と「品質」「味」の次元になっている。「すらっと茶」「ヤンロン茶」の位置づけがちょっと解せない。このデータでは2次元評価をしているといってよい。
(3)茶飲料データ(cha2.sav) 日経流通新聞データ
小売り店の無糖茶に対する評価。2003年6月14日(土)
もとは%データである。頻度との関係は明白なのでパーセンタイルデータのまま分析する。回収数は110社,回収率57.9%。日経リサーチ社集計
CORRESPONDENCE TABLE=ALL(10,10) /plot=RPOINTS CPOINTS biplot.
出力 煌が高いので価格が利いている。
excel からのデータの読み込み例
次のようなexcelファイルを用意する。(cha3.xls)このファイルをSPSSのメニューからファイル→開く→データ→ファイルの種類(Excel(*.xls)を選択→ファイル名を指定し読み込む。
このようにexcel から読み込むと半角8文字を超える変数の場合,変数ラベルを自動的につけてくれる。
シンタックス・エディタ(ファイル→新規作成→シンタックス)に次の値ラベルを付けるシンタックスを書き,走らせる。
value labels rowcat_
1 "テレビCM"
2 "味・素材・製法"
3 "ブランド力"
4 "パッケージデザイン"
5 "商品コンセプト"
6 "ネーミング"
7 "キャンペーン・イベント"
8 "希望小売価格"
9 "テレビCM以外の広告"
10 "POPなど店頭販促"
.
その後,次のシンタックスを走らせる。
CORRESPONDENCE TABLE=ALL(10,10) /plot=RPOINTS CPOINTS biplot.
無糖茶の調査 http://www.macromill.com/client/r_data/20030627mutou/main.html
(4)http://www.littera.waseda.ac.jp/faculty/stok/kogi2002/ca_1.ppt(鈴木督久氏@早稲田大学) 9頁のファッションブランドのデータを分析せよ。(Netscape からだとpowerpoint が別に開くのでデータを取り出すことができる)
*****************************.
value labels
rowcat_
1 "ミヤケ"
2 "オンワード"
3 "カルバン"
4 "サンヨー"
5 "シャネル"
6 "ベルサーチ"
7 "アルマーニ"
8 "セリーヌ"
9 "ダーバン"
10 "東京スタイル"
11 "ニナリッチ"
12 "ハナエモリ"
13 "バーバリ"
14 "ベネトン"
15 "ミッソーニ"
16 "ラルフロレン"
17 "レノマ"
18 "ワールド"
.
CORRESPONDENCE TABLE=ALL(18,20) /plot=RPOINTS CPOINTS biplot.
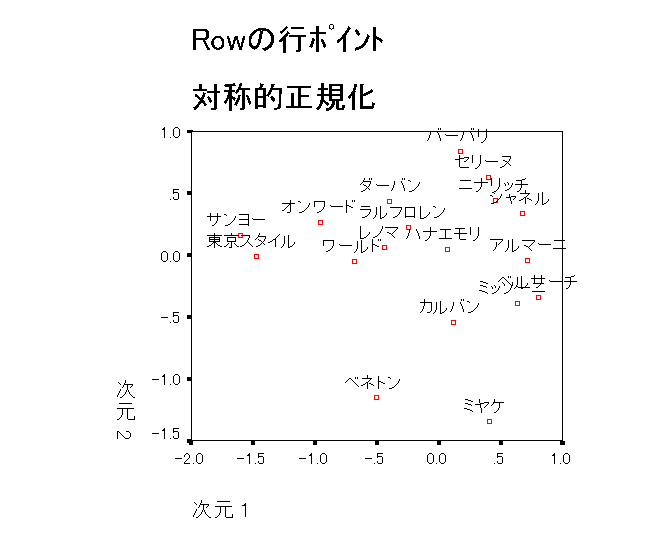
|
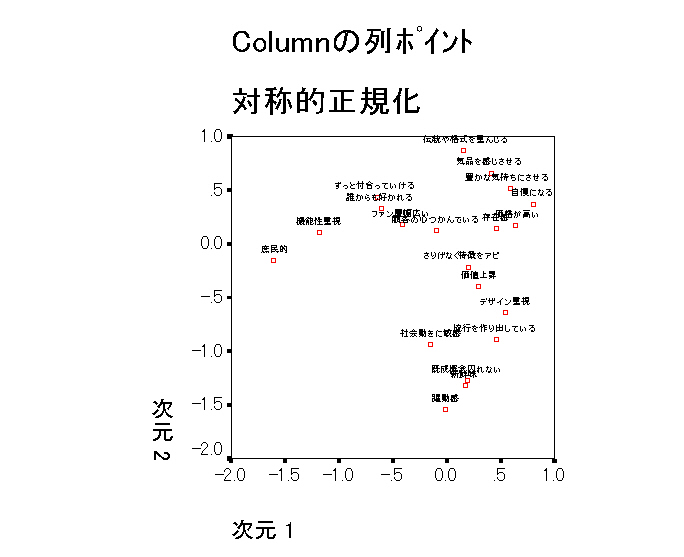
|
1軸,2軸とも鈴木氏のSASの結果とプラスマイナスが逆になっている。プラスマイナスが逆転することは数学的に意味のあることではないので気にすることはない。
*****************************.
既定値だと図のフォントが大きすぎる。→図をダブルクリックして図表エディタ
図のフォント部分をクリックしてマークをつけボタンTをクリックし,フォントサイズを4など小さい文字にし→適用→閉じる
応用1(該当数型)
(1)softdrink.sav (1,0) を用いて,行列計算からクロス表を求めよ。
(2)クロス表の結果から対応分析を実行せよ。syntax を使う。correspondence
(3)homals の結果と比較せよ。
*(1).
matrix.
get d/variables=coke to up7.
print d.
comput cross=t(d)*d.
print cross.
end matrix.
*(2).
data list free/COL1 to COL8.
begin data.
20 5 1 0 15 8 1 8
5 17 7 6 4 3 11 2
1 7 8 4 1 1 5 1
0 6 4 7 0 1 5 1
15 4 1 0 16 5 0 5
8 3 1 1 5 11 1 5
1 11 5 5 0 1 11 1
8 2 1 1 5 5 1 9
end data.
var labels
col1 "coke"/
col2 "dietcoke"/
col3 "dietpepsi"/
col4 "diet7up"/
col5 "pepsi"/
col6 "sprite"/
col7 "tab"/
col8"7up".
CORRESPONDENCE TABLE=ALL(8,8)/plot=CPOINTS.
*---------------------.
行変数にラベルをつけるには,先頭に ROWCAT_ という変数をつくり,各行にvalue(値)をつけ,value labels を設定する。
このデータの場合,対称行列なので,行と列の変数の次元の得点は一致する。列ポイントだけを参照すればよい。
出力 correspondenseのみ
応用2(MCA アイテムカテゴリ型)
(1)softdrink2.sav (1,2) を用いて,行列計算においてダミー行列を作成しそのクロス表を求めよ。
(1)なしで(2)だけでも結果がでる。
(1)は変数の呼び出し以外は一般ルーティンなので,ほかの処理にも簡単に使うことができる。
(2)クロス表の結果から対応分析を実行せよ。syntax を使う。correspondence
(3)homals の結果と比較せよ。応用1とも比較せよ。
*(1).
matrix.
get x/variables=coke to up7.
print x.
*数量化3類のルーティンを使用.
*design の出力を1,2,3...とするため num.
compute num={1,2,3,4,5,6,7,8,9,10,11,12,13,14,15}.
compute num=t(num).
compute nsample=nrow(x).
*変数数 #nvar.
compute #nvar=ncol(x).
* cmaxs 各itemの最大カテゴリー数.
compute cmaxs=cmax(x).
*カテゴリの1,0展開 結果を z に.
compute z=x(:,1).
loop i=1 to #nvar.
compute x1=x(:,i).
compute x1={num(1:cmaxs(1,i),1);x1}.
compute d=design(x1).
compute #row1=nsample+cmaxs(i).
compute d=d((cmaxs(i)+1):#row1,1:cmaxs(i)).
compute z={z,d}.
end loop.
*最初に使ったデータ列を削除.
compute z=z(:,2:ncol(z)).
*以上 dummy 行列の生成.
print z.
compute cross=t(z)*z.
print cross.
end matrix.
*(2).
data list free/COL1 to COL16.
begin data.
20 0 5 15 1 19 0 20 15 5 8 12 1 19 8 12
0 14 12 2 7 7 7 7 1 13 3 11 10 4 1 13
5 12 17 0 7 10 6 11 4 13 3 14 11 6 2 15
15 2 0 17 1 16 1 16 12 5 8 9 0 17 7 10
1 7 7 1 8 0 4 4 1 7 1 7 5 3 1 7
19 7 10 16 0 26 3 23 15 11 10 16 6 20 8 18
0 7 6 1 4 3 7 0 0 7 1 6 5 2 1 6
20 7 11 16 4 23 0 27 16 11 10 17 6 21 8 19
15 1 4 12 1 15 0 16 16 0 5 11 0 16 5 11
5 13 13 5 7 11 7 11 0 18 6 12 11 7 4 14
8 3 3 8 1 10 1 10 5 6 11 0 1 10 5 6
12 11 14 9 7 16 6 17 11 12 0 23 10 13 4 19
1 10 11 0 5 6 5 6 0 11 1 10 11 0 1 10
19 4 6 17 3 20 2 21 16 7 10 13 0 23 8 15
8 1 2 7 1 8 1 8 5 4 5 4 1 8 9 0
12 13 15 10 7 18 6 19 11 14 6 19 10 15 0 25
end data.
var labels
col1 "coke "/
col3 "dietcoke"/
col5 "dietpepsi"/
col7 "diet7up"/
col9 "pepsi"/
col11 "sprite"/
col13 "tab"/
col15 "7up"/
col2 "xcoke"/
col4 "xdietcoke"/
col6 "xdietpepsi"/
col8 "xdiet7up"/
col10 "xpepsi"/
col12 "xsprite"/
col14 "xtab"/
col16 "x7up".
CORRESPONDENCE TABLE=ALL(16,16)/plot=CPOINTS.
出力
頭にx がついているのがそのソフトドリンクを飲まない側の数量。2値型なので,例えば,pepsi と xpepsi を結ぶと原点を通る。原点からの距離は頻度の逆数に比例する(参照)。homals の数量と同じ結果になる。数量化3類の駒澤型カテゴリ数量とは値が違うが比例している。homals,数量化3類,多重対応分析は多少の誤差があっても基本的に一致する。
応用1のタイプが数量化3類の該当数型に対応し,応用2がアイテム・カテゴリー型に対応する。応用2は多重対応分析(MCA)といいhomals と対応し,数値が一致する。応用2(アイテム・カテゴリー型)の場合,主成分分析と数値が対応している。応用1タイプの場合,使えないデータがでてくる。すべて該当なしのデータ。また,応用2タイプの分析は主成分分析の結果と対応する。このようなことからこのタイプのデータの場合応用2(アイテム・カテゴリー型)のように分析することを薦める。
応用1と応用2の比較は繁桝ほか(1999)において説明している,数量化3類と対応分析の結果の違いである。読んでください。(なお,このように対応分析でも数量化3類でも両者の結果を出すことができるので,このことは数量化3類と対応分析の違いを表しているものではありません)
繁桝算男・柳井晴夫・森敏昭編著『Q & A で知る統計データの解析 DO's and DON'T』サイエンス社(1999) p183-186
各指標間の関係については,下の指標および説明を読んでちょうだい。おっと結局数量化3類スクリプトを走らせることになる。数量化3類マクロを読めば,関係はわかる。
問題
テキストのスキー板のデータを分析し,何次元までが妥当か答えよ。何を根拠にそう考えられるか述べよ。
スキー板データ
CORRESPONDENCE TABLE=ALL(16,10) /plot=RPOINTS CPOINTS biplot.
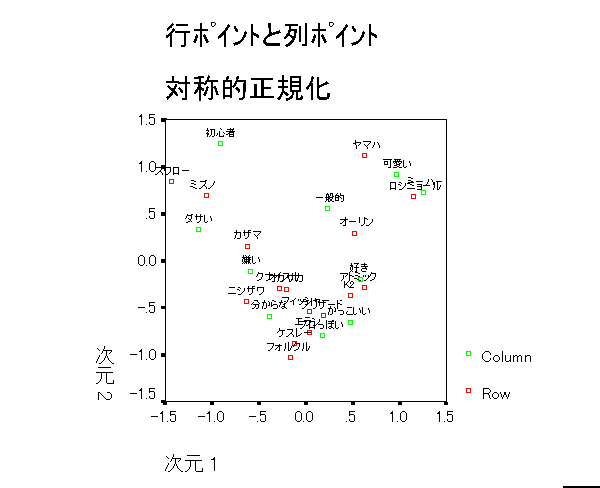
|
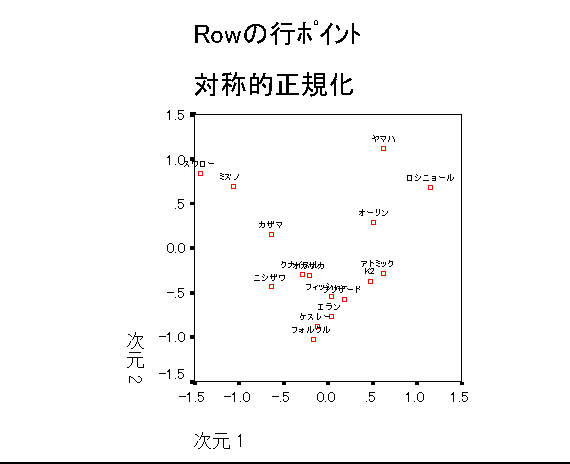
|
|
U字型(馬蹄形の話参照)であることがわかる。基本的に1次元。しかし2次元目も解釈できる。
CATPCA はHomals よりも広範なデータを扱うことができる。名義尺度,順序尺度,間隔尺度の指定ができる。オプションも多彩である。変数指定はカテゴリー数を指定しなくていいので簡略化されているが,その他のオプションが多いのでちょっと面倒。
ソフトドリンクのデータ(softdrink2.sav)を使う。
spss
分析→データの分解→最適尺度法→最適尺度水準「一部の変数が多重名義でない」→定義→変数指定(「分析変数」のすべての変数を反転したまま→尺度と重み付けの定義→最適尺度水準(多重名義をクリック)→続行
→出力→カテゴリ数量に全変数を指定→続行
→「作図」カテゴリ→「カテゴリプロット」にすべての変数を入れる→続行→ok
数量化とカテゴリポイントを主としてみる。
このように少ないサンプルの場合,オブジェクトを直接見るのもいい。
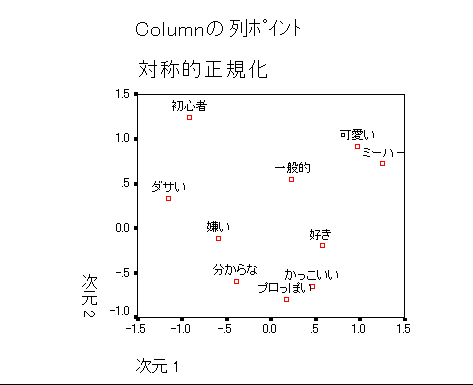
駒澤のデータ(H3test.sav)を処理してみよう。出力 多重名義の場合はhomals と同じ結果となる。
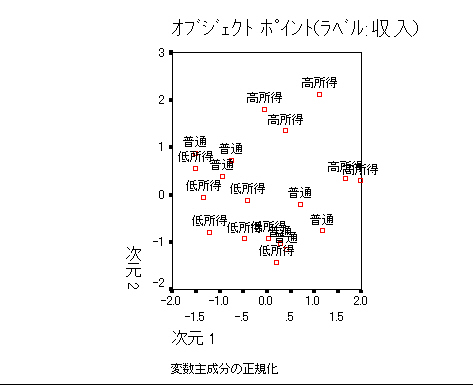
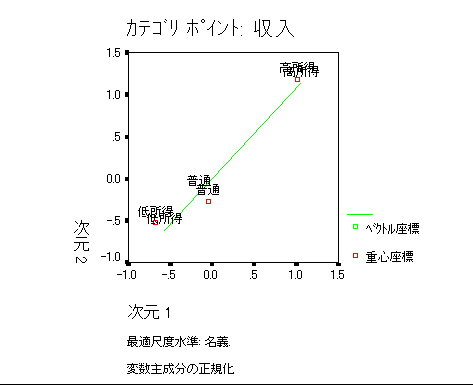
同様に指定していく。変数はa1~a5。「作図」カテゴリにおいて オブジェクト→「オブジェクトのラベル付け」にa1(収入)を指定してみよう。
最適尺度水準(名義)の場合は次のように オブジェクトポイントがラベルづけされ,各個体の収入があらわされ,収入がきっちり分かれていることがわかる。多重名義の場合はこのようにきれいに分かれない。
|
|
どの処理がやりやすいか,どの出力が見やすいか。
数量化3類スクリプトのために作った出力をベースに見てみよう。
- 各アイテムカテゴリー×軸(アイテムカテゴリを評価する)
最初に見る項目はカテゴリ数量
(1)カテゴリ数量(重みづけ係数)(駒澤型;HOMALS,対応分析の主座標型)HOMALS では数量化として出力される。
出力はHOMALS、対応分析の主座標型
(2)相関係数(主成分分析との比較のため)数量化3類スクリプトのみ出力
(3)相関の2乗(対応分析)
- 各アイテムカテゴリー(因子分析に対応するものなし)
(1)quality(対応分析)
(2)絶対的寄与率(対応分析)
(3)イナーシャ(inertia)(対応分析)
(4)求めた軸までの寄与率
- 各軸のアイテム(変数)を評価する(因子分析の負荷量)
(1)範囲(数量化3類) (範囲はカテゴリ頻度に強く影響される欠点をもつ)
(2)判別測度(HOMALS)=相関の2乗(西里)
- 軸を評価する(因子分析の寄与率)
(1)寄与率(対応分析;Greenacre;岩坪,1987; catpca)
(2)信頼性クロンバックのα係数(西里, catpca)
(3)χ2検定(西里)
(4)固有値・特異値(数量化3類,homals,対応分析)
- すべての次元に対する変数の貢献(因子分析の共通性にあたる)
(1)マス(対応分析)
- サンプル数量(homals ではオブジェクトスコア)(因子分析の因子得点)
(1)標準座標(数量化3類,HOMALS) 下の「カテゴリ数量,サンプル数量(オブジェクトスコア)の標準化の仕方」を参照のこと
数量化3類のアイテム、カテゴリの評価(1995/12/11)
数量化3類のアイテムとそのカテゴリの評価はきわめて単純である。アイテムカテゴリ数量でそのカテゴリを評価し、アイテム内のカテゴリ数量の範囲(range)を使ってアイテムの相対的重要度を評価する。HOMALS は判別測度(discriminant measure)* (SPSSのマニュアルではときどき判別手段(^^;)と訳されている)という指標を使っている。カテゴリ数量の分散であり、そのアイテムとその軸との相関の2乗である。欠測値があると1を超えることがあると書いてある。それなら、最初から相関係数を求めてその2乗にしたほうがいいのではないだろうか。
Greenacre(1993,1994)は対応分析のために多くの指標を作成している。彼の作った SimCA 2 がそれを出力するようにしているらしい。その指標の計算の仕方は Greenacre(1993)にもあるが、Greenacre(1994)のほうがわかりやすいであろう。
カテゴリごとの相関の2乗の和(因子分析の共通性にあたる)、inertia (大隅ほか(1994)では質量と訳しているが、massとは分けて「慣性」というべきだろう)。また軸ごとの数量、相関の2乗、inertiaをだす。しかし、多重対応分析には相対的寄与率は意味がないとしています。そして、アイテムごとの軸との相関およびその2乗を使っています。ということは、HOMALS と一緒だ。
そうすると求めるのは、
(1)アイテムカテゴリについては数量、およびアイテムカテゴリごとの軸との相関またはその2乗(相対寄与度)
(2)アイテムごとの軸との相関またはその2乗を使用することになる。補足的にアイテムカテゴリ数量の範囲。
(3)その軸の寄与率は固有値そのものを使わず、
Q=(アイテムの数)
固有値の平方根(√λk)が1/Qより大きいものを使用し、
| Q |2 | 1 |2
| --- | × |√λk - - |
| Q-1 | | Q |
を固有値の代わりに使い、寄与率をだす。上の式はGreenacre(1993)のもので、Benzecri(1979) は√λk ではなく λkを使う。Greenacre(1994)によると、Benzecriの式ではその寄与率を過大評価をしている。
1/Qはランダムに反応したとき(つまりアイテム間に関連がない場合)の相関の2乗の平均値(つまり最小値)Greenacre(1993,p154)。(大隅らのp156-157に1/Qについて気になることが書いてある)
まあ、こんなところが指標になる。
欠損値がない場合についてマクロで組んでみました。(95/12/24)
現在のマクロ とスクリプト。スクリプトのほうが図をプロットするなど進化している。例によって駒澤(1982)のデータを分析する。
>(3)その軸の寄与率は固有値そのものを使わず、
Nishisato(1994)でも1/Q つまり(1÷アイテム数)以上の固有値が意味のある解であることを示している。
EVL .4946646239 .4242423801 .3457090356 .2740414348
.2646050059 .1967375198 .0000000000 .0000000000
となっているので、.3333より大きい解は3つ。
各軸の寄与率の計算を Benzecri の方法とGreenacre の方法を改訂した計算し、その固有値の比率をだす。その改訂は次の点にある。
Q=(アイテムの数)
1/2
固有値の平方根(λk) が1/Qより大きいものを使用し、→固有値が1/Qより大きいものを使用し、
| Q |2 | 1/2 1 |2
| --- | × |(λk) - - |
| Q-1 | | Q |
固有値 Benzecri ratio Greenacre ratio
.495 .059 .756 .308 .452
.424 .019 .240 .228 .334
.346 .000 .004 .146 .214
Greenacre(1994)はBenzecriの式では過大評価するといっているが、まさにそのとおりになっている。Greenacre(1993)の式で固有値の平方根をとる根拠はよくわからないが、こちらのほうが妥当な数値がでてくるようだ。今後の検討が必要であろう。
>(1)アイテムカテゴリについては数量、およびアイテムカテゴリごとの軸との相
>関またはその2乗(相対寄与度)
これは、Gifi(1990,p112) の式から求める。
>そのカテゴリの反応率をx%とすると、
>
> | 100-x |1/2 | 100-x |1/2
> -|----------- | ≦ y ≦ |----------- |
> | x | | x |
>
>|は絶対値の意味ではなくカッコの代わりに使ってます。
もとは頻度で記述しています。最大値はカテゴリ数量の長さを意味するから、y
を最大値で割ると相関係数(負荷量)が求められる。この2乗がGreenacre(1993)
の相対寄与率。
(HOMALS のカテゴリー数量)
相関係数= -----------------------------------------
(サンプル数)-(そのカテゴリーの頻度)
-------------------------------------
(そのカテゴリーの頻度)
>(2)アイテムごとの軸との相関またはその2乗を使用することになる。補足的に
>アイテムカテゴリ数量の範囲。
(2-2) Greenacre(1993)のアイテムカテゴリごとの絶対寄与率も求めることがで
きた。その元となるinertia(慣性)をアイテムごとに合計するとアイテムと軸
の相関係数の2乗となる。
inertia = ((HOMALS のカテゴリー数量)**2)*(そのカテゴリーの頻度)
頻度 数量 loading 相関**2 inertia 絶対寄与
↓ ↓ ↓
相関 相対寄与率 絶対寄与率
(inertia/固有値)
-------------------------------------------------------------
****** 第 1 相関比解 ******
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A1 7.000 1.861 .676 .456 .297 .200
2 8.000 -.225 -.091 .008 .005 .003
3 5.000 -2.246 -.642 .412 .309 .208
範囲 相関2乗(discrimination measure)
---> 4.107 .610
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A2 8.000 -.745 -.301 .090 .054 .037
2 4.000 -1.266 -.313 .098 .078 .053
3 5.000 2.749 .785 .616 .462 .312
4 3.000 -.908 -.189 .036 .030 .020
範囲 相関2乗(discrimination measure)
---> 4.015 .625
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A3 11.000 -.911 -.498 .248 .112 .075
2 9.000 1.114 .498 .248 .137 .092
範囲 相関2乗(discrimination measure)
---> 2.025 .248
****** 第 2 相関比解 ******
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A1 7.000 -.777 -.242 .058 .038 .030
2 8.000 2.031 .703 .495 .297 .233
3 5.000 -2.162 -.530 .280 .210 .165
範囲 相関2乗(discrimination measure)
---> 4.193 .545
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A2 8.000 1.582 .548 .300 .180 .142
2 4.000 -3.182 -.675 .456 .365 .286
3 5.000 .165 .040 .002 .001 .001
4 3.000 -.250 -.045 .002 .002 .001
範囲 相関2乗(discrimination measure)
---> 4.764 .548
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A3 11.000 .904 .424 .180 .081 .064
2 9.000 -1.105 -.424 .180 .099 .078
範囲 相関2乗(discrimination measure)
---> 2.010 .180
COLNAME
****** 第 3 相関比解 ******
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A1 7.000 .975 .247 .061 .040 .038
2 8.000 -.823 -.232 .054 .032 .031
3 5.000 -.048 -.010 .000 .000 .000
範囲 相関2乗(discrimination measure)
---> 1.798 .072
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A2 8.000 -1.435 -.405 .164 .098 .095
2 4.000 -1.896 -.328 .107 .086 .083
3 5.000 .074 .015 .000 .000 .000
4 3.000 6.232 .905 .819 .696 .671
範囲 相関2乗(discrimination measure)
---> 8.128 .881
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
A3 11.000 .759 .290 .084 .038 .037
2 9.000 -.928 -.290 .084 .046 .045
範囲 相関2乗(discrimination measure)
---> 1.687 .084
-------------------------------------------------------------
Greenacre(1993)はMCA においては相対寄与率(相関**2)を意味のないものとしています。それでも、頻度が少なくてカテゴリ数量が大きくなっているものをチェックするのには役立ちそうです。
絶対寄与率を見ていると、フランスで、慣性とよびたくなる気持ちがわかります。
また、Greenacre(1993)は固有値の寄与率においても、MCAでは役に立たないという評価をしています。この点は、役に立っていない固有値まで拾っているという点に一つ問題がありそうです。
数量化3類のカテゴリー数量 (1996/03/10)
ソフトドリンクのデータを使います。
このデータの固有値は、
Columns 1 - 5 (切り捨て)
.481 .151 .099 .088 .075
Columns 6 - 10
.049 .030 .023 .000 .000
で許容最小固有値(1/アイテム数)は .125 ですから、最初の2軸のみが有効ということになります。
駒澤型で処理すると、
カテゴリ数量
freq 1 2
COKEO 20.00 1.54 -.74
2 14.00 -2.20 1.05
DIET7O 7.00 -2.76 2.88
2 27.00 .72 -.75
DIETCO 17.00 -1.63 -.91
2 17.00 1.63 .91
DIETPO 8.00 -2.38 .43
2 26.00 .73 -.13
PEPSIO 16.00 1.63 -3.34
2 18.00 -1.45 2.97
SPRITEO 11.00 1.16 6.97
2 23.00 -.55 -3.34
TABO 11.00 -2.53 .02
2 23.00 1.21 -.01
UP7O 9.00 1.47 6.64
2 25.00 -.53 -2.39
となり、その範囲は、次のようになります。
(a)範囲は意味のあるもの?
(1)範囲 (数量化3類: range:駒澤型)
1 2
COKEO 3.74 1.79
DIET7O 3.47 3.62
DIETCO 3.25 1.82
DIETPO 3.11 .57
PEPSIO 3.08 6.30
SPRITEO 1.71 10.31
TABO 3.74 .03
UP7O 2.00 9.03
同じく、アイテムの効果を調べる指数の判別測度を見てみると次のようになります。
(2)相関係数の2乗(HOMALS: discriminant measure)
1 2
COKEO .79 .02
DIET7O .46 .05
DIETCO .61 .02
DIETPO .40 .00
PEPSIO .55 .23
SPRITEO .15 .53
TABO .71 .00
UP7O .18 .36
本来、数量化3類のアイテムカテゴリ数量は次元間においての比較をするものではありませんが、(1)と(2)と比較すると、(1)は2軸があまりにも大きな値になっています。これは駒澤型の特徴です。これを修正する方法は2つ考えられます。1つは軸を同等に扱うやりかたです。つまり、それぞれの軸で正規化することになります。これは標準座標(standard coordinate)と呼ばれます。2つめはそれぞれの分散(inertia)をあらわすように正規化することです。これはHOMALSや対応分析がしている方法です。正準正規化とSPSSでは呼んでいます。主軸(principal axis)とか主座標(principal coordinate)とも呼ばれます。
(3)範囲 (数量化3類: range:正規化)
1 2
COKEO 2.59 .70
DIET7O 2.41 1.41
DIETCO 2.26 .71
DIETPO 2.16 .22
PEPSIO 2.14 2.45
SPRITEO 1.19 4.01
TABO 2.60 .01
UP7O 1.39 3.51
(4)範囲 (数量化3類: range:正準正規化)
1 2
COKEO 1.80 .27
DIET7O 1.67 .55
DIETCO 1.57 .28
DIETPO 1.50 .09
PEPSIO 1.49 .95
SPRITEO .83 1.56
TABO 1.80 .00
UP7O .96 1.37
(4)だと、判別測度に近いイメージをあらわしていますが,それでも大きな値をとってます。
(b)距離の問題
これは、(a)の問題とも絡んできます。
2次元をプロットしたときに、駒澤型だと、軸間の距離はなにも保証されていないですから、目で見たまま判断してはいけません。しかし、(3)または(4)だとそれぞれの意味をもった距離として判断することが一応可能です。注意も必要です。下の説明を読んでください。
(c)統計的利用
この点では正準正規化がもっとも多くの利用価値があります。他の指標を作り出す起点として正準正規化したカテゴリ数量を利用できます。
相関係数(負荷量)との関係はすでに説明しました。
説明している分散の大きさも正準正規化したカテゴリ数量から求めます。
cokeo(1)= (.74151^2)*20/(34)=0.3234335765
cokeo(2)= (-1.05930^2)*14/34 =0.4620479665
(カテゴリ数量の2乗)*頻度/総頻度
なお、1軸の合計は .4817449385(精確な固有値)*8= 3.853959508
(5)軸×カテゴリーごとのinertia(分散)
1 2
COKEO .323 .007
2 .462 .010
DIET7O .364 .039
2 .094 .010
DIETCO .307 .009
2 .307 .009
DIETPO .309 .001
2 .095 .000
PEPSIO .291 .120
2 .259 .107
SPRITEO .101 .361
2 .048 .173
TABO .482 .000
2 .230 .000
UP7O .133 .268
2 .048 .096
これから、SASでも求めている偏inertia を求めます。
cokeo(1)= 0.3234/(.4817*8) = 0.08392152792
(6)inartia(分散)に対する相対的貢献率
1 2
COKEO .084 .006
2 .120 .009
DIET7O .094 .032
2 .024 .008
DIETCO .080 .008
2 .080 .008
DIETPO .080 .001
2 .025 .000
PEPSIO .076 .099
2 .067 .088
SPRITEO .026 .298
2 .013 .142
TABO .125 .000
2 .060 .000
UP7O .034 .221
2 .012 .080
暫定的結論
(a)いくつかの性質から、カテゴリ数量には正準正規化数量(主座標)がよいだろう。
(b)個体数量は正規化(標準座標)しているほうが判断しやすい。(c)(a)(b)からHOMALSの選択は妥当なものだろう。
(d)ただし、バイプロットの場合は解釈に注意を要する。(バイプロットの場合はいつものことではある)
(e)数学的には対応分析のほうが明晰である。とくに、固有ベクトルからカテゴリー数量を求めるところ。さらに、いろんな指標の導出が簡単。行列演算を中心とするでの記述は Greenacre(1993)Correspondence analysis in practice.Academic Press 付録2がよい。SASのマニュアルも参照のこと。
(f)SPSSマクロのような行列演算で処理する場合、対応分析で求めて、そのバリエーションとしてMCAの各種指標を求めるのがよさそうである。メモリを少なくする処理としては、数量化3類型もあるでしょう。
sasの対応分析(mca)の見方 指標の意味の復習(1996/03/04)
SASに対応分析が付いていますが、対応分析になれていないと結果を見るのが困難でしょう。対応分析をまともにやってくれるソフトとしてSASを使うこともあると思います。
いつもの駒澤(1982)のデータを使います。
プログラム。
*********************************************
data media;
input
(NUM A1 A2 A3 A4 A5 A6 A7) (2.0).
;
cards;
1 1 1 1 2 1 210
2 1 3 2 1 2 1 8
3 2 1 1 1 1 518
4 3 4 2 2 2 630
5 1 4 1 1 1 315
6 2 3 2 2 2 212
7 2 1 1 1 1 622
8 1 3 1 2 2 312
9 3 2 2 2 3 525
10 1 1 2 1 2 2 8
11 3 1 1 1 31020
12 2 3 1 2 1 410
13 2 1 2 2 2 314
14 1 3 2 2 1 1 6
15 3 2 1 1 3 928
16 2 4 1 1 310 8
17 1 2 2 1 1 310
18 2 1 2 1 3 425
19 3 1 1 2 1 628
20 2 2 1 1 2 628
;
proc corresp dimens=3 mca ;
table a1-a3 ;
run;
*******************************************
次元はとりあえず3にしています。既定値は2です。変数 A4-A7 はここではいらないのですが、入れてます。
******************************************
The Correspondence Analysis Procedure
Inertia and Chi-Square Decomposition
ここが数量化3類の固有値に対応する。
↓
Singular Principal Chi-
Values Inertias Squares Percents 5 10 15 20 25
----+----+----+----+----+---
0.70332 0.49466 32.4109 24.73% *************************
0.65134 0.42424 27.7967 21.21% *********************
0.58797 0.34571 22.6512 17.29% *****************
0.52349 0.27404 17.9554 13.70% **************
0.51440 0.26461 17.3371 13.23% *************
0.44355 0.19674 12.8904 9.84% **********
------- -------
2.00000 131.042 (Degrees of Freedom = 64)
座標。数量化3類のアイテムカテゴリ数量
(ただし、主軸なので、値は小さい)
(principal inertia で割ると駒澤型カテゴリ数量)
↓
Column Coordinates
Dim1 Dim2 Dim3
1 -0.92065 0.32949 0.33700
2 0.11111 -0.86154 -0.28448
3 1.11114 0.91717 -0.01664
1 0.36841 -0.67116 -0.49603
2 0.62624 1.35008 -0.65562
3 -1.35996 -0.06980 0.02548
4 0.44919 0.10600 2.15444
1 0.45079 -0.38365 0.26239
2 -0.55097 0.46891 -0.32069
Summary Statistics for the Column Points
因子分析の 頻度÷ 固有値に対する
共通性に対応 (総度数× 相対的貢献度
アイテム数) (合計=1)
Quality Mass Inertia
1 0.576009 0.116667 0.108333
2 0.557012 0.133333 0.100000
3 0.692040 0.083333 0.125000
1 0.554824 0.133333 0.100000
2 0.661182 0.066667 0.133333
3 0.618338 0.083333 0.125000
4 0.856700 0.050000 0.141667
1 0.512417 0.183333 0.075000
2 0.512417 0.150000 0.091667
固有値に対する相対貢献度(各次元別)
第1次元A1のカテゴリ1は 0.49466*0.199907=0.098886
のinertia をもつ。
Partial Contributions to Inertia for the Column Points
Dim1 Dim2 Dim3
1 0.199907 0.029855 0.038326
2 0.003327 0.233278 0.031212
3 0.207992 0.165237 0.000067
1 0.036584 0.141574 0.094896
2 0.052854 0.286426 0.082890
3 0.311574 0.000957 0.000156
4 0.020395 0.001324 0.671320
1 0.075315 0.063607 0.036510
2 0.092052 0.077742 0.044624
軸とカテゴリの相関係数の2乗つまり負荷量の2乗
この和が上のQuality
Squared Cosines for the Column Points
Dim1 Dim2 Dim3
1 0.456400 0.058457 0.061152
2 0.008230 0.494831 0.053951
3 0.411545 0.280403 0.000092
1 0.090484 0.300308 0.164032
2 0.098044 0.455678 0.107459
3 0.616498 0.001624 0.000216
4 0.035606 0.001983 0.819111
1 0.248372 0.179898 0.084146
2 0.248372 0.179898 0.084146
*****************************************
SASはMCA指定のとき人のほうの得点、サンプル数量を出力しない。これを出力したいときはダミー行列(DESIGN MATRICS)を使う。
数量化3類なら、アイテムごとの範囲をHOMALSならアイテムごとの判別測度(軸とアイテムの相関係数の2乗)を出してくれます。対応分析のMCAはアイテムを考慮することはないのが欠点です。もちろん計算することはできます。
SASのMCAは欠損値をカテゴリとするオプションがありますが、一般には欠損値のあるオブザベーション(ケース)は削除されます。
- 順序尺度の問題 意味のない解 次のところ参照
-
数量化3類,多重対応分析のアイテム内のカテゴリの数
Nishisato(1994)は双対尺度法(対応分析)でのカテゴリの数とη2の問題を論じていて、あまりカテゴリ数が多いと過剰にη2があがることを例をだして説明している。10くらいあるともういけない。そんなことも考慮しなければならない。
- 欠測値・欠損値
西里(1982)p190-192。
(a)無反応が多い問に関しては「無反応」という選択肢を設けて無反応も一種の反応として双対尺度法にかけることがある。これは無反応からも情報をくみとろうというわけで、可能性としては大変興味深い。しかし、経験的にはこの方法は思ったほどうまくいかない。無反応の影響があまりにも大きくですぎることがよくある。...。他方、無反応の理由がたとえば極端な政治思想をもつゆえでというなら、....本質的な情報を担うこととなる。
(b)「ノーコメント」がある被験者群から一貫してみられるとき最適解は全群をノーコメント群とその他に分けるもので、次の解が解釈のできる解であった。...(c)いまノーコメントと無反応は同じものと考えれば、...。例えば2個の無反応を示した被験者からは(n-2)個の反応が得られたこととし、それらに対応するデータ行列Fの部分は0で置き換えるということにすると、...。この方法は、項目が比較的同質的で、無反応が無作為的に生起する場合には満足のできる方法であることが、...。DUAL2ではこの方法を用いており、...。
Nishisato(1994)ではさらに多くの言及をしている。4つの方法としてまとめている。さらに、imputation法についても3つあげている。
林(1993) p84
なお、利用上、ここで注意しておきたいことはliである。ある質問に対する回答として、“その他、DK”、“無回答”まで含めて考えれば、liは常に質問項目数に等しくなる。しかし、“その他、DK”、“無回答”を除いて考えることが、事象をはっきりさせるために望ましいこともあるので、....。また、すべてのカテゴリーを用いずに分析に適応したカテゴリーのみを取り上げて、この方法使うとすると人によりliは異なったものになる。欠測データがある場合も同様である。こうした取り扱いも考慮に入れた方がいいので、liは人によって等しくないとしておくのがよい。なお、“その他、DK”を計算に入れると、われわれの経験では一般的に回答したものと、回答しないものとを識別する軸が必ず出てくるものであり、あとは大きな差がないことがわかっている。
---------------------------
以上の見解から、欠測値をもったデータを含めて分析することが認められていることがわかる。
- 頻度とカテゴリ数量との関係
低頻度のカテゴリは大きな値をとるので過大に評価してしまう。
- カテゴリ数量,サンプル数量(オブジェクトスコア)の標準化の仕方
(初出95/12/11 09:17一部改)
アイテムカテゴリ数量にいくつか求め方がある。このとき、個体数量をどうするかも同時に問題になる。
(1)アイテムカテゴリ数量をまず求めて、それから個体数量を求めるもの
基準化するというときに、
(a)アイテムカテゴリ数量を基準化する。
(b)個体数量を基準化する。
の2つがある。
そして、
(a)をベースにして個体数量を求める。=個体数量の分散はη2(固有値)
→SPSSの数量化3類
(b)をベースにしてアイテムカテゴリー数量を求める。
→駒澤(1982)の数量化3類=アイテムカテゴリの分散は 1/η2
(c)(a)と(b)を同時に満たす。
このタイプの提案もあるようだが、バイプロットするときに問題があるだろう。
(2)個体数量をまず求めて、アイテムカテゴリ数量を求める
SPSSのCATEGORIES のなかの最適尺度化の HOMALS である。
当然上記の(b)である。アイテムカテゴリ数量の分散はη2(固有値)
(1)と(2)はバイプロットしたときの意味が異なり、(Gifi,1990)
(1)の場合、その個体の反応したカテゴリの重心にその個体が位置する。
(2)の場合、そのカテゴリに反応した個体の重心(平均値)がそのカテゴリの位置である。
これは個体数量、カテゴリ数量の求め方からいえるものです。
----------------------------------------------------------------
SPSS数量化3類 駒澤数量化3類 HOMALS
----------------------------------------------------------------
カテゴリ数量
平均 0 0 0
分散 1 1/η2(1/固有値) η2(固有値)
SD 1 1/η η
個体数量(オブジェクト数量)
平均 0 0 0
分散 η2(固有値) 1 1
SD η 1 1
カテゴリ数量中心 カテゴリ数量中心 個人数量中心
-----------------------------------------------------------------
Greenacre(1993)は平均0分散1の座標を標準座標(standard coordinate)、平均0、分散がη2(固有値)の座標を主座標(principle coordinate)と呼んでいる。
標準座標は標準得点としての読みとりができるので便利である。
----------------------------------------------------------------
SPSS数量化3類 駒澤数量化3類 HOMALS
----------------------------------------------------------------
カテゴリ数量 標準座標 変形 主座標
個体数量 主座標 標準座標 標準座標
----------------------------------------------------------------
ところで、標準座標のアイテムカテゴリ数量をそのまま標準得点として解釈していいかというと問題がある。Gifi(1990,p112)によると、カテゴリ数量はそのアイテムの中での反応率に依存してそのとる範囲が決まってくる。Gifi の計算のしかただと(主座標)、
そのカテゴリの反応率をx%とすると、
| 100-x |1/2 | 100-x |1/2
-|----------- | ≦ y ≦ |----------- |
| x | | x |
|は絶対値の意味ではなくカッコの代わりに使ってます。
---------------------------------------------------------------------
Homls の数量 標準座標 駒澤座標
最大値 最大値 最大値
---------------------------------------------------------------------
10%の項目 3 3/η 3/η2
50%の項目 1 1/η 1/η2
90%の項目 1/3 (0.333) 1/(3η) 1/(3×η2)
---------------------------------------------------------------------
(ηは0から1の間の値なので、η、η2で割ると数が大きくなります)
となって、最初から最大値に不公平のある八百長ゲームのような得点なのです。
その値に対して、標準得点のような解釈をするのは問題がありそうです。もっともηがある程度以上小さければそれほど問題はなさそうだが、反応率の低い項目を過大評価することになるのは同じです。
個人数量のほうは標準得点のように解釈するのは意味があるでしょう。絶対値が1.96(両側5%)または2.58(両側1%)を超えていると普通じゃない得点だと考えていいでしょう。
また、バイプロットした意味を考えると、変数中心のほうがおそらく解釈しやすいでしょう。以上の点から、駒澤(1982)の数量化3類は普通の考えからは逸脱しているようですが、利用を考慮した数量化といえるでしょう。
Gifi,A.(1990)Nonlinear multivariate analysis. Wiley.
Greenacre,M.J.(1993)Correspondence analysis in practice. Academic Press.
Greenacre,M.J. and Blasius,J. eds.(1994)Correspondence analysis in
social sciences. Academic Press.
駒澤勉(1982)数量化理論とデータ処理 朝倉書店
参考
いつも使っている、駒澤(1982)の例を分析すると、
HOMALS VARIABLES =A1(3) A2(4) A3(2).
HAYASI3 IVAR=A1 A2 A3.
などのプログラムを使う。
データは
NO A1A2A3 A1(3) A2(4) A3(2)
------------
1 1 1 1
2 1 3 2
3 2 1 1
4 3 4 2
5 1 4 1
6 2 3 2
7 2 1 1
8 1 3 1
9 3 2 2
10 1 1 2
11 3 1 1
12 2 3 1
13 2 1 2
14 1 3 2
15 3 2 1
16 2 4 1
17 1 2 2
18 2 1 2
19 3 1 1
20 2 2 1
----------------------
SPSS行列言語を使っての分析。
固有値
.4946646239 .4242423801 .3457090356 .2740414348 .2646050059
.1967375198 .0000000000 .0000000000
固有ベクトル
A1 .16899 -.06531 .07399 -.09714 .15641
2 -.02039 .17076 -.06246 .13840 -.14489
3 -.20396 -.18179 -.00365 -.08545 .01286
A2 -.06762 .13303 -.10891 -.19770 .03158
2 -.11495 -.26759 -.14395 .22571 .03122
3 .24963 .01384 .00559 .14699 .05505
4 -.08245 -.02101 .47305 -.01874 -.21759
A3 -.08275 .07604 .05761 .06967 .14171
2 .10113 -.09294 -.07041 -.08515 -.17320
HOMALS型 カテゴリ数量
A1 .92065 -.32949 .33700 -.39390 .62321
2 -.11111 .86154 -.28448 .56121 -.57733
3 -1.11114 -.91717 -.01664 -.34648 .05123
A2 -.36841 .67116 -.49603 -.80165 .12583
2 -.62624 -1.35008 -.65562 .91526 .12442
3 1.35996 .06980 .02548 .59604 .21934
4 -.44919 -.10600 2.15444 -.07600 -.86701
A3 -.45079 .38365 .26239 .28250 .56466
2 .55097 -.46891 -.32069 -.34528 -.69014
標準化 type(SPSS数量化3類)(分散1)
A1 1.30900 -.50587 .57315 -.75245 1.21153
2 -.15797 1.32272 -.48383 1.07206 -1.12234
3 -1.57984 -1.40814 -.02829 -.66187 .09960
A2 -.52381 1.03044 -.84363 -1.53137 .24461
2 -.89040 -2.07277 -1.11506 1.74838 .24187
3 1.93362 .10717 .04334 1.13859 .42641
4 -.63866 -.16275 3.66421 -.14517 -1.68548
A3 -.64095 .58902 .44626 .53965 1.09770
2 .78338 -.71992 -.54543 -.65957 -1.34164
駒澤型数量化3類 カテゴリ数量
A1 1.86116 -.77665 .97480 -1.43737 2.35523
2 -.22461 2.03077 -.82288 2.04792 -2.18185
3 -2.24625 -2.16191 -.04812 -1.26435 .19363
A2 -.74477 1.58203 -1.43482 -2.92530 .47554
2 -1.26599 -3.18233 -1.89645 3.33985 .47019
3 2.74926 .16453 .07370 2.17499 .82895
4 -.90807 -.24986 6.23196 -.27732 -3.27660
A3 -.91131 .90432 .75898 1.03087 2.13396
2 1.11382 -1.10529 -.92764 -1.25995 -2.60817
あなたの数量化3類がどのタイプか調べてみて下さい。
- 数量化3類,対応分析と主成分分析(96/03/02 23:31 nifty forum への書き込み一部改)
そういえばこんなところにも書いていた([fpr 271] quant 3 etc. ソフトドリンクのデータの分析
FACTOR
/VARIABLES cokeo diet7o dietco dietpo num pepsio spriteo tabo up7o
.
**************************************.
主成分分析結果
*****************.
Factor Matrix:
Factor 1 Factor 2 Factor 3
COKEO -.88034 -.15747 -.11714
DIET7O .66274 .25504 .13341
DIETCO .77978 -.11682 .10975
DIETPO .64227 .01484 -.20050
NUM -.35304 .19065 .83650
PEPSIO -.74711 -.46386 .11469
SPRITEO -.40162 .75269 .13069
TABO .83549 .02754 .11785
UP7O -.41541 .54417 -.44942
Final Statistics:
Variable Communality * Factor Eigenvalue Pct of Var Cum Pct
COKEO .81352 * 1 3.94950 43.9 43.9
DIET7O .52207 * 2 1.21864 13.5 57.4
DIETCO .63374 * 3 1.02959 11.4 68.9
DIETPO .45293 *
NUM .86071 *
PEPSIO .78649 *
SPRITEO .74491 *
TABO .71269 *
UP7O .67067 *
*******************************************************.
おおっと、SPSSの既定値で処理したのですが、SASとだいぶ違っています。SASの結果を示します。
(a)主成分分析(3因子にしているのは元の論文が3因子のため)
(a-1)
Eigenvalues of the Correlation Matrix: Total = 8 Average = 1
1 2 3 4
Eigenvalue 3.8540 1.2114 0.7936 0.7095
Difference 2.6425 0.4179 0.0841 0.1023
Proportion 0.4817 0.1514 0.0992 0.0887
Cumulative 0.4817 0.6332 0.7324 0.8211
(a-2)
Initial Factor Method: Principal Components
Factor Pattern
FACTOR1 FACTOR2 FACTOR3
COKEO -0.88627 -0.13329 0.07592
DIETCO 0.78369 -0.13768 -0.17552
DIETPO 0.63560 0.03636 0.48826
DIET7O 0.67680 0.22182 0.34464
PEPSIO -0.74162 -0.47644 0.18420
SPRITEO -0.38630 0.73031 -0.37997
TABO 0.84395 0.00213 -0.19842
UP7O -0.42521 0.60319 0.42678
****************************************************
こんなち違っていていいのかな? 主成分分析だよ。
SPSS最新バージョン 11.5.2.1 で再分析したところ,SASと同じ結果になりました。SPSSよどうしてたんだ。
****************************************************
数量化3類
*******************************************************
****** 第 1 相関比解 ******
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
COKEO 20.000 1.539 .886 .785 .323 .084
2 14.000 -2.199 -.886 .785 .462 .120
範囲 相関2乗(discrimination measure)
---> 3.738 .785
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
DIETCO 17.000 -1.627 -.784 .614 .307 .080
2 17.000 1.627 .784 .614 .307 .080
範囲 相関2乗(discrimination measure)
---> 3.254 .614
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
DIETPO 8.000 -2.379 -.636 .404 .309 .080
2 26.000 .732 .636 .404 .095 .025
範囲 相関2乗(discrimination measure)
---> 3.110 .404
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
DIET7O 7.000 -2.759 -.677 .458 .364 .094
2 27.000 .715 .677 .458 .094 .024
範囲 相関2乗(discrimination measure)
---> 3.474 .458
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
PEPSIO 16.000 1.633 .742 .550 .291 .076
2 18.000 -1.451 -.742 .550 .259 .067
範囲 相関2乗(discrimination measure)
---> 3.084 .550
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
SPRITEO 11.000 1.159 .386 .149 .101 .026
2 23.000 -.555 -.386 .149 .048 .013
範囲 相関2乗(discrimination measure)
---> 1.714 .149
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
TABO 11.000 -2.533 -.844 .712 .482 .125
2 23.000 1.212 .844 .712 .230 .060
範囲 相関2乗(discrimination measure)
---> 3.745 .712
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
UP7O 9.000 1.471 .425 .181 .133 .034
2 25.000 -.530 -.425 .181 .048 .012
範囲 相関2乗(discrimination measure)
---> 2.001 .181
COLNAME
****** 第 2 相関比解 ******
COEFFIC
頻度 数量 loading 相関**2 inertia 絶対寄与
COKEO 20.000 -.736 -.133 .018 .007 .006
2 14.000 1.052 .133 .018 .010 .009
範囲 相関2乗(discrimination measure)
---> 1.789 .018
(以下略)
*********************************************************.
EVL
.4817449385
.1514303712
.0991959242
.0886850551
.0759004020
.0490976246
.0303108730
.0236348114
**************
固有値・固有ベクトルの計算は行列言語のほうが精確(spss-lメーリングリストからの情報)であるためか若干の違いが生じている。SASの結果と比べた方がいい。主成分分析の固有値から変数数わったものつまり、%のほうと一致する。
主成分分析の負荷量と数量化3類のloading(相関係数) の項目の数値が一致します。もともとhomals では相関係数の2乗(判別測度)を出力することに注意してください。
それでは、アイテムカテゴリ数量と負荷量の関係はどうなっているか。以前に説明しているのでわかるでしょう。しかし、その説明したところの式に一部もれがありました(^^;。平方根にする部分 1/2 を入れていなかったのです。
その部分を含めて,メーリング・リストから引用
**********************
欠損値がない場合、何%の人が反応したかで、そのそのカテゴリの得点の可能な最大値を求めることができます。
(a)のコークの場合(20:14 58.8%,41.2%)
-.74151
相関係数=-----------------------=-0.8858
sqr((100-58.8)/58.8)
(b)のダイエットコークの場合(17:17 50.0%,50.0%)、
0.78369
相関係数=-----------------------=0.78369
sqr((100-50)/50)
(c)ダイエットペプシの場合(8:26 23.5%,76.5%)
1.14584
相関係数=-----------------------=0.6350
sqr((100-23.5)/23.5)
と誤差の範囲におさまっていて上の値と一致する。
********************
上で使っている対応分析の軸得点は,アイテムカテゴリ数量に固有値をかけたものです。SASの対応分析の結果を示すと次のようになります。homalsの結果もこのようになるはず。
******************
SASを使用した対応分析の軸得点(b-2)
Column Coordinates
Dim1 Dim2 Dim3
COKEO -0.74151 -0.11152 0.06352
COKEX 1.05930 0.15932 -0.09074
DIETCO 0.78369 -0.13768 -0.17552
DIETCX -0.78369 0.13768 0.17552
DIETPO 1.14584 0.06555 0.88023
DIETPX -0.35257 -0.02017 -0.27084
DIET7O 1.32920 0.43564 0.67686
DIET7X -0.34461 -0.11294 -0.17548
PEPSIO -0.78660 -0.50534 0.19538
PEPSIX 0.69920 0.44919 -0.17367
SPRITEO -0.55858 1.05603 -0.54943
SPRITEX 0.26715 -0.50506 0.26277
TABO 1.22034 0.00307 -0.28692
TABX -0.58364 -0.00147 0.13722
UP7O -0.70868 1.00532 0.71130
*******************
なお、一週間にその飲料を飲んだことを示すカテゴリのみで分析した場合、主成分分析の結果とは対応しない。このことは、数量化3類が
(1)特性項目への該当が任意の数である
をベースに説明していて、これが基本のようにも思えるが、
(2)特性項目がアイテム・カテゴリーでそれぞれのアイテム中のカテゴリーに必ず1つ該当する。
タイプを基本と考え,この数値を解釈するほうがいいのではないだろうか。(1)のタイプの処理を数量化3類と違うものとしたほうがよさそうである。
SPSSの計算はWindows95上で6.1.3を使って計算しました。SASはEWS4800上の6.10 です。