因子数決定指標の特徴
香川大学経済学部 堀 啓造
counter: (2004/7/20からの累積)
最終更新日:
AIC、BIC、CAIC
|AIC
|BIC
|CAIC
|CFI
|χ2検定
|GFI, RGFI
|MAP
|NFI
|NNFI(TLI)
|PA-EIG-M, PA-EIG95
|PA-SMC-M, PA-SMC95
|RAW-EIGEN
|GFI, RGFI
|RMSEA
|SMC-EIGEN
|TLI (NNFI)
|はじめに
|結果
|クラステー分析
|考察
|討論
|関連ページ
|文献
|図表
- はじめに
- 基礎データ
- 結果
- SMC-EIGEN (対角SMCの固有値0以上基準)
- RAW-EIGEN (固有値1以上基準、カイザー基準、ガットマン・カイザー基準)
- NFI
- PA-SMC-M, PA-SMC95 (対角SMCの平行分析)
- PA-EIG-M, PA-EIG95(平行分析)
- MAP
- GFI, RGFI
- AIC、BIC、CAIC(情報量)
- AIC
- BIC
- χ2検定
- CAIC
- RMSEA
- NNFI (TLI)
- CFI
- クラステー分析
- 考察
- 討論
- 関連ページ
- 文献
はじめに
因子数の決定法にはいくつかある.その中で固有値系,残差系のMAP、情報量系,適合度指標系の決定法について検討する.
Zwick and Velicer(1986)は因子数の決定法について検討してMAP (Velicer, 1976)が一番よくて,ついで平行分析 (Horn, 1965)がよいことを見いだしている.ただし,共通性の大きさ×サンプルサイズの交互作用を見いだしている.このとき共通性が大きいときはサンプルサイズの影響は少ないことを見いだしている.共通性が中または低の時にサンプルサイズが大きいほうが因子数の推定がよい.このことから,共通性が中または低のときの因子数決定法の当てはまりの良さを検討すればよいことになる.一般に因子負荷量の平均は0.5~0.7程度であるので,因子負荷量の平均が0.6を中心に検討する.因子抽出法は最尤法のみを扱うのでサンプルサイズ300を中心に扱う.1因子の指標となる項目数は最低4は必要なので,5項目+4項目の2因子構造を中心に分析する.
適合度指標についてMarsh, Hau and Wen(2004)がHu and Bentler(1999)に頼ることの問題点を指摘している.そしてreject するだけならχ2検定が良いことを示している.Marsh らの論文からも適合度指標の性質がよくつかめていないことがわかる.また,Nasser and Wisenbaker(2003)はparceling について検討しているが,それが指標の数の問題を紛れ込ませていることは間違いない.本研究の結果から見て,指標の数はあきらかに適合度指標の大きさを左右する要因であるにもかかわらず,parceling したときの指標数を統制していない.逆にいうとNasser and Wisenbaker(2003)は指標数を変えたときの乱数データの指標の動きを検討したものといえる.
Velicer et al.(2000)はMAP よりも平行分析のほうがいいことを見いだしている。また、MAPでは2乗和を4乗和のほうがよりよいことも見いだしているが、今回は4乗和については検討しない。
本研究では因子負荷量をモデルとして想定して,母相関行列を作成している.基本的に母相関行列における因子数決定法の切れ味を試した.補足的に母相関行列に対応する乱数データ行列を作成し,各指標を検討したが,乱数データ行列を大量に作成し,平均値を比較するということはしていない.それらは必要があれば今後やってみるが,excel で処理しているので必要が生じないことを願う.
基礎データ
因子抽出法は最尤法を使う。
300ケース、因子負荷量0.6の5項目と4項目の各1因子計2因子をベースとして分析する。
この因子間相関を0から0.95まで0.05刻みで変化させていき検知できない因子間相関から因子数決定指標の感度を調べる。0ならば検知できないことであり、1であればどのような因子間相関でも検知できることになる。0.95 で検知できれば1.0 で検知できないとする。
それぞれのケース、因子負荷量、項目数を操作して考察する。
(1)因子負荷量は0.5, 0.6, 0.7, 0.8.
(2)項目数は4項目と2,5,7,9,11項目
(3)サンプルサイズは100, 200, 300, 500, 1000
(4)2項目についてもうひとつを5項目をベースとして負荷量と項目数を動かす。さらに5項目のほうを動かしてみる。
(5)3因子の場合も負荷量別、サンプルサイズ別求めている。
以上がモデル行列についてである。
(6)乱数データを生成して標本誤差の問題も少し考えてみる。ここに乗せているのは1例である。これは極端に乱れた例.もう一つは比較的まともなもの.さらに1指標を含むもの.これは固有値1の基準がよくないことを示す.1指標の場合のRAW-EIGEN(固有値1以上の基準)は因子数が多い、、正しい、少ないの3つの場合が起こることを示している。
感度が高すぎると思われる0.85以上を赤、感度が低いと思われる0.50以下に黄色、全く感知しない0に水色のマークを付けている。
結果
最尤法は1因子1指標の場合不適解となる。そのためモデル行列の分析の場合、1因子1指標以下の因子は摘出できない。そのため因子抽出後に求められる指標はこの制限を受ける。固有値系の指標とMAPはこの制限を受けない。
SMC-EIGEN (対角SMCの固有値0以上基準)
SMC-EIGENは微妙な因子にも極めて鋭敏に反応する。因子以外にもサンプルの誤差から生じる変動にも反応する。項目数の多いランダム変数の因子に鋭敏に反応し、多目の因子数を推定する。モデル行列の場合、極めて高い相関の因子でも峻別できるというメリットはある。
因子あたり項目数、共通性の大きさ、サンプルサイズにほとんど影響されない。
母相関行列においてはほとんど影響されず、感度は相関係数 0.95以上である。
母相関行列における因子数決定法としてはもっともよい方法といえるが、実データではノイズにあまりにも弱く使い物とならない。
RAW-EIGEN (固有値1以上基準、カイザー基準、ガットマン・カイザー基準)
母相関行列(モデル)においては、極めて安定した行動を示す。
(1)5+4の負荷量に関しては一貫して0.8の感度である。
(2)項目数は多い方が感度が高い。項目が少なく(4+3)でも0.75を保っている。
(3)サンプルサイズの影響は全くない。
(4)2指標の場合は相関係数 0.60になると因子を感知できない。
この点を追加分析する。下に表がある。3因子まで拡張すると2-2-2のとき0.55 となる。表からみると最小指標数が感知できる因子間相関に大きく影響する。これからみると少ない指標数の場合、 0.55~0.70の因子間相関がある場合に検知できなくなる。
| 各因子の指標数 | 感知できない因子間相関
|
| 4-4-2 | 0.60
|
| 4-3-2 | 0.60
|
| 3-3-3 | 0.70
|
| 2-2-2 | 0.55
|
| 5-4 | 0.80
|
| 5-2 | 0.65
|
| 4-2 | 0.65
|
| 3-2 | 0.60
|
| 2-2 | 0.55
|
(5)サンプル誤差の影響は大きい。
RAW-EIGEN はマイナー因子に敏感に反応する。サンプル誤差にも反応する。1指標因子とサンプル誤差が合わさると共通因子としてしまう。
因子あたり項目数、共通性の大きさ、サンプルサイズにあまり影響されない。but 上の問題あり。母相関行列においてはあまり影響されず、指標数が4以上ならば、感度は相関係数 0.8であり高い。
母相関行列の因子数決定法としてはいいものであるが、実データの因子数決定法として問題がある。
NFI
NFI がRAW-EIGENと似た動きをし、サンプルサイズの影響を受けないし、項目数の影響も極めて小さい。ただ、負荷量の影響は多少受ける。また、1指標+サンプル誤差の影響はない。これは感度の設定の問題かもしれない。RAW-EIGENが0.80 に対してNFIは0.70 である。また、2指標の場合 NFI は項目数に影響される。項目数が多い場合は2指標因子を検出しない。サンプル誤差を含む場合は2指標の時にも因子数を多く抽出する傾向がある。
PA-SMC-M, PA-SMC95(対角SMCの平行分析)
(1)1因子に2指標以上。1指標の場合は検知しない。
(2)負荷量・指標数・サンプルサイズに関しては少し影響を受け,いずれも大きい方が感度が高くなる.あまり気にする必要はない. 2指標の場合は負荷量0.4, サンプルサイズ100での感度が低い。
PA-EIG-M, PA-EIG95 (平行分析)
(1)負荷量の影響を少し受ける。負荷量が小さくなると感度が鈍る。
(2)項目数の影響も少し受ける。項目数が少ない方が感度が鈍い。
(3)サンプルサイズの影響も多少ある。サンプルサイズが小さくなると感度が鈍る。
(4)2指標の場合も同様である。固有値1の基準に比べ感度が鈍い方向に動いているので、それぞれにおいて小さい値のものは感度が鈍いという範囲に入る。
(5)一般的にMAPよりも感度が高いが、負荷量の高いとき(0.80以上)のときにはMAPよりも感度がわずかに低い(MAP 0.65,PA 0.75, .70)。このときにはMAPよりも少ない因子数となる。
(6)一般に対角SMCの平行分析よりも感度が低いが、2指標のときの負荷量0.4, サンプルサイズ100 それぞれにおいて感度が高くなっている。
MAP
母相関行列のデータより、1指標にはまったく反応しない。2指標にも反応しない。3指標の場合には(平均)負荷量0.6以下、4指標の場合も負荷量が0.5以下なら反応しない。
(a)項目数による影響は強く、項目数が多いほうが微妙な違い(因子間相関が高い時にも)を検出する。
(b)負荷量が高いときのほうが敏感である。.80の時には相関0.8の因子も検出する。
(c)サンプルサイズの影響は全くない。
GFI, RGFI
GFI, RGFIはMAPに似ている。
GFI, RGFI はサンプル誤差によって大きく乱れることがあり、規定の値に達しないこともある。
AIC、BIC、CAIC
AIC、BIC、CAICの順に感度が鈍くなる。AICは極めて感度が高い。
AIC
(1)AICは感度が高く、負荷量の大きさにあまり影響をうけない。0.50 の時に相関.75にさがるが、負荷量0.60 の時には0.85である。
(2)項目数の影響はほとんどない。
(3)サンプルサイズの影響は、負荷量0.6 ではあまり大きくない。サンプルサイズ100でも0.7 である。負荷量0.5だと顕著になる。
2項目指標の場合、サンプル数が小さい場合(100->0.30)、感度がはっきり低くなる。
(4)最尤法との関係から、1指標の場合は感知しない。
(5)AIC2のマイナスを基準にするとほぼBICと同じ因子数を採用する。
BIC
(1)負荷量の影響はかなりある。0.5 の負荷量のときは相関0.5 とかなり感度が低くなっている。負荷量0.7のときには相関0.85と感度が高くなる。
(2) 項目数の影響はそれほど大きくないが、項目数が少ないほうが感度は高くなる。また、負荷量が小さくなるほど項目数の影響は強くなる。
(3)サンプルサイズの影響はかなりある。100人と1000人との間で、感度が低い(0.5)
から感度が高い(0.85)に変化する。
(4)2指標の場合、負荷量、項目数、サンプルサイズとも大きな影響がある。負荷量なら0.5以下, 項目数では9項目以上、サンプルサイズでは200人以下で感知しなくなる。
CAIC
CAICはBICよりも少し感度が悪くなる。
χ2検定
BICとほぼ同じ変動。BICよりもサンプル誤差の影響を受けることがある。
モデル行列においてはBICにかなり似ている。乱数データによる乱れがBICに比べると大きい。
(1)負荷量の影響はかなり大きい.
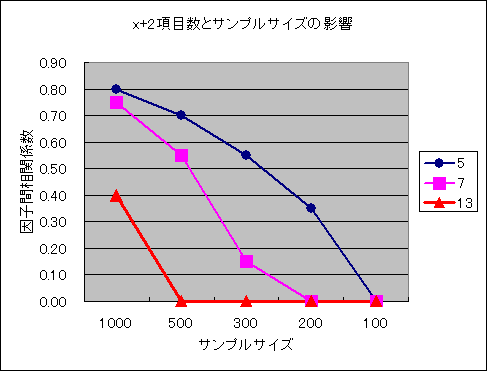
(2)2指標の場合にBICとのずれが大きくなる.χ2検定は2指標の場合に大いなる特徴がある.2指標の場合,項目数,サンプルサイズの影響は顕著である.下図にあるように,2指標の因子がある場合,もう一方の項目数が多いと2指標の因子を検知しにくいが,サンプルサイズが大きくなると検知するようになる.つまり,マイナー因子でも検出することになる.
(3)ランダムデータにおいても従来いわれているようにサンプルサイズによって影響されることはない。もっとも,もともとサンプル誤差の影響は受けやすく,1指標の場合よりも一般にサンプル誤差効果の影響が大きいと言えよう.
(4)過小推測は因子間相関がかなり高いときに生じるだけでそれほど多くの場合に生じるものでないことがわかった。
RMSEA
(1)負荷量の影響はかなり受ける。0.7以上で感度が高く、0.5で感度は鈍る。
(2)項目数の影響は少ないが、他と違って項目数が少ないほうが感度が高くなる。
(3)サンプルサイズの影響もかなりある。サンプルサイズが小さくなると感度が鈍くなる。
(4)2項目因子は負荷量によって感度が大きく異なる。負荷量0.5のときは因子と認めない。負荷量0.8 の時には好感度(0.9)となる。項目数の影響も大きく、9項目以上だと因子とならない。7項目以下で中程度の感度がある。
(5)サンプル誤差の影響はχ2と同程度に受ける。
NNFI (TLI)
(1)負荷量の影響は中程度受ける。負荷量が小さいほうが感度が低い。NFI よりも影響が大きい。
(2)項目数の影響はほとんど受けないが、 RMSEAと同じく項目数が少ないほうが感度が高くなる。
(3)NFI と違ってサンプルサイズの影響を受ける。いずれも中程度の感度を保っている。
(4)2項目の場合の負荷量の影響は大きい。負荷量が小さくなると感度が悪くなる。
項目数の影響も強く、もう一方の因子の項目数が増えると因子と認めなくなる。サンプルサイズの影響も高く100サンプルの場合因子を認めなくなる。
(5)サンプル誤差の影響をかなり受ける。
CFI
NNFI と似ている。少しNNFI よりもよい。
クラスター分析
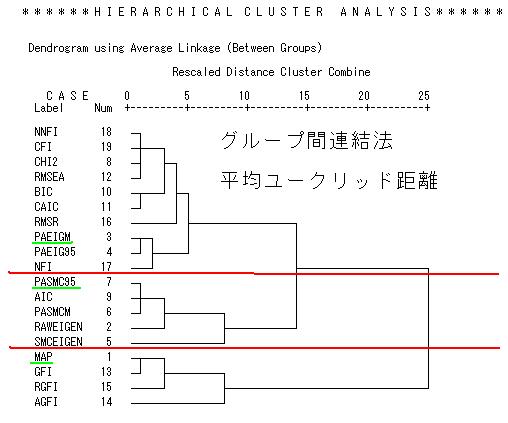
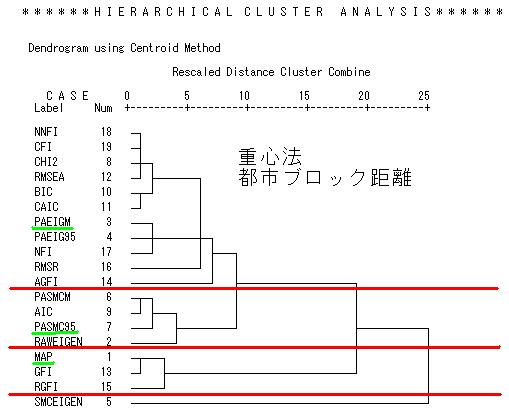
各指標の同一因子とみなす因子間相関をデータとしてクラスター分析を行った。クラスター分析は安定した手法とみなすべきでなく、複数の手法を使っても同一のクラスターに属するならば比較的に安定したものと言える。ここではSPSSの既定値にしている、平均ユークリッド距離をグループ間連結法を使った結果と、都市ブロック距離を重心法を使った結果を例としてあげた。
両者を比較してみると基本的には3つのクラスターがある。
(1)PA-SMC95、AIC、PASMC-M,RAW-EIGENの高い相関を検知する、高感度群
(2)MAP, GFI, RGFI の因子負荷量や項目数によって低感度となる一部低感度群
(3)χ2, BIC, PA-EIGEN,RMSEA, CFI, NFI など多数の中感度群
これらに、AGFI, SMC-EIGEN が位置づけを変える指標となる。
考察
(1)単純に母相関行列だけを考えると対角SMCの固有値0以上基準(SC-EIGEN)がもっともよい。また、固有値1以上基準(RAW-EIGEN)もそれについでよい。サンプル誤差を含むデータを分析すると対角SMCの固有値0以上基準は誤差に対して敏感の反応して因子数を多く推測する傾向にある。サンプル誤差を含むデータにおいては、固有値1以上基準は因子数を少なくとも多くともただしくとも推測する。ランダムデータにおいて特に1指標因子を感知することが多く生じるため因子数を多く推測することがあり、Hornの批判の正しさを示した。
(2)MAP はモデル行列、サンプル誤差を含む行列においてもかなり安定した方法となった。因子数を少な目に推定する理由も明らかになった。
MAPは母相関行列のデータより、1指標にはまったく反応しない。2指標にも反応しない。3指標の場合には(平均)負荷量0.6以下、4指標の場合も負荷量が0.5以下なら反応しない。という特徴を持つ.ランダムデータにおいてもそれほど乱れることはない.項目数による影響は強く、項目数が多いほうが微妙な違い(因子間相関が高い時にも)を検出する。負荷量が高いときのほうが敏感である。.80の時には相関0.8の因子も検出する。サンプルサイズの影響は全くない。これらのことは尺度作成上は少しきつい基準であるがいい性質といえるだろう.
(3)通常の平行分析(PA-EINGEN)については,MAP よりもいい性質も持っている.つまり通常の項目数であると負荷量が低くてもある程度の感度を保っている.しかし,2指標の場合は母相関行列でも検知する.このためMAPよりも因子数を多く推測する可能性がある.マイナー因子のないきれいなデータの場合は,MAP と同等か,それ以上によい推測をする.
PA-EIGENとPA-EIGEN95の違いは小さいが多少PA-EIGEN95のほうが感度が鈍い.
(4)対角SMCの平行分析においても平均(PA-SMC-M)と95%上限(PA-SMC95)との差は小さい.ランダムデータにおいて1指標をほとんど検知することはない.しかし,母相関行列においても2指標因子は検出する.また,サンプル誤差にも反応する.欠点はあるが,比較的安定して正しいか多い因子数を推定する.ただし,因子間相関が極端に高いときには少ない推測もする.
(5)χ2検定は通常いわれているほど悪い検定ではない.ただし,ここでは変数の数がかなり少ないのでそのために悪くない検定となっているのかもしれない.このデータではサンプルサイズの影響はあまりない.負荷量の影響のほうが大きい.
(6)情報量系は従来言われているAIC>BIC>CAIC の順に感度が高い.BIC が比較的χ2検定に似ているのは意外である.母相関行列でも感度の違いが明確であり,特にサンプルサイズの影響は顕著である.AICの場合,2指標の検出はサンプルの多い場合に感度が高く,サンプルが少ないと感度は極めて低くなる.このことがサンプルサイズについてAICがとやかくいわれていることかもしれない.マイナー因子のないきれいな尺度の場合,サンプルサイズによって影響されないが,マイナー因子を含む場合やサンプル誤差の大きい場合はサンプルサイズが大きくなると,因子数の多いモデルを選択することになる.
BIC, CAIC の場合は4指標の場合でもサンプルサイズの影響を受ける.また,BIC, CAIC の場合2指標の場合負荷量が0.5だと感知しない 2指標の場合,AICよりも鈍感になる.これらは因子数決定においていい方向に作用する.
AIC,BIC,CAICは他の因子分析後計算する適合度指標よりも安定していい因子数を推定する.ただし,MAPや平行分析よりもいいということはない.
(7)他の適合度指標はχ2検定と同じくサンプル誤差に影響される.特にMAPよりも優れた指標はない.
(8)以上のことから,堀の提案する,MAPを最低因子数,対角SMCの平行分析95を最大因子数として挟み込んで因子数を決めるのがよい.
MAPの弱点は因子数を少なく推定することである.これは特に指標の数が少ないときに生じる.また3指標,4指標ある場合でも因子負荷量の小さい因子は検知しない.このことはきちんとした尺度化をするときには長所となるが,単に因子間構造を知りたいときや項目のサンプリングが適切でないときは短所になる.また,既成の尺度でも3項目を指標とする尺度が見受けられるが因子負荷量の低い場合は因子として認められなくなる.例えばThurstone & Thurstone(1941)は各3項目7因子となっているが,7因子は認めない.
対角SMCの平行分析95は対角SMCの平行分析平均よりもはっきりとよいという結果はでていないが,対角SMCの平行分析の共通の弱点であるマイナー因子や標本誤差の影響で因子数を多めに推測する傾向があるという点からこのほうがいいだろう.マイナー因子のない場合はどちらでも同じ結果になることが多い.対角SMCの平行分析95を使用するのは特に2指標や3指標の因子を検出するためである.MAPでは見逃す因子を検出する.
そして,MAPの結果と対角SMCの平行分析95結果が同じ数になるということは,指標の数,因子負荷量,マイナー因子の点からみてよい尺度といえるので極めて好ましい尺度と言える.
討論
探索的因子分析に関して
探索的因子分析において因子数を決定する唯一の指標はない.それぞれの長所,短所,特徴を捉えて使用すべきである.このとき,MAPと対角SMCの平行分析95がもっとも強力な組合せといえる.両者の因子数が一致するときは,その因子として断定できる.そして,それは,マイナー因子のない,適切な因子に対する指標数を確保した非常によい尺度となっていることを示す.
通常の平行分析もこの分析からはかなりよい.ただし,2指標の因子も抽出するかどうかの問題がある.これを認めるときはMAPのかわりに積極的に使ってもよい.
尺度を作成するときにはいい尺度とは何かを考えるべきであろう.適度な指標数を確保することは重要である.また,小さい負荷量の場合は多めの指標がいるであろう.心理学の尺度の場合,0.50程度の負荷量の尺度も考慮することになるであろう.この場合,安定してこの因子を探索的に抽出するには5指標あるほうがいいであろう.このようなことを考えるとMAPの示す因子数は極めて示唆的である.
単にそこにある構造を考えたいときにはこのような縛りを考える必要はない.このときは通常の平行分析をMAPのかわりに使っても良い.Thurstone & Thurstone(1941)の21変数データ分析の例(因子数決定法,斜交回転法,階層因子分析 ppt p47-51)からもMAPや対角1の平行分析だけで決定することはできない.因子間の相関が高いときは因子数を少なく推定することは避けられない.
SEMの適合度指標としての問題
SEMの適合度指標の検討は重みや指標数を操作することなく検討されることが多い.しかし,本研究から,母相関行列においてさえこれらのパラメータを考慮する必要があることがわかった.ここで問題なのはどれぐらいのトレランスが必要かということである.これを設定しないとMarsh, Hau and Wen(2004)が指摘しているように排除することは難しい.彼らの指摘のようにおそらく排除という点ではχ2検定が最もよいのであろう.ただし,χ2検定はBICによく似た結果を示すのである.
AICはサンプルサイズが大きいときによくないと言われているが,実情はそれほどでない.これはなにによるものであろうか.実際には1指標に対しても敏感であるように適合度としていい指標なのである.これが使えないのはデータに汚れがだいぶ入ることによるのであろう.AICがダメなのではなくデータがダメなのである.そうするとどの程度の感度が必要なのかということを考えなくてはならない.マイナー因子を感じなくて敏感な指標というのは現状ではあり得ないだろう.どの程度のどのような感度を要求するかを考えて適合度指標を使うべきなのである.
http://www.ec.kagawa-u.ac.jp/~hori/内の関連ページ
- 因子分析の因子数決定法 script
- MAP, 対角SMCの平行分析などの因子数を求めるSPSSスクリプト
-
excel vba program for faccon.exe コバンザメアプリ (愛称:忍者ハットリ君)
- 服部環氏のfaccon.exe をexcel から起動し、出力をexcel に取り込むプログラム。因子分析の因子数決定の各種指標と因子分析の結果を出力する。直接obliminとHarris-Kaiserの斜交回転をオプションとして増やした。
-
Parallel analysis
- 平行分析の文献レビューをした。固有値1基準の問題を明確に示した。
-
因子数決定法の検討: Holzinger and Swineford(1939)の知能データをもとにして
- Holzinger and Swineford(1939)の知能データを使用して、異なるサンプルにおいても安定して同一因子数を指す指標を探索した。MAP と平行分析はこれに合格した。
-
因子分析練習帳 1 Gorsuch(1983)変数サンプリング
- 高次因子がある場合の変数の選択によって選択する因子構造が異なってくることを示した。最尤法と最小2乗法の適合度指標からの因子数を比較し、母相関行列でさえ最小2乗法での適合度指標はあてはまりがよくないことを示した。
-
因子数決定におけるマイナー因子の影響の検討
- MacCallumらのデータを使用して、マイナー因子がある場合の指標への影響を調べた。MAPは比較的影響をうけない。対角SMCの平行分析はマイナー因子の影響を受けることがある。
-
因子数決定法,斜交回転法,階層因子分析
- 2004年2月の好み研での講演のpowerpoint.このときよりも発展させたのがこのページの話。
-
因子数を決定する
- 香川大学経済学部での講義資料。MAP, 対角SMCの平行分析の基本的性質について簡略に述べる。
文献
Gorsuch, R. L. (2003). Factor analysis. in J. A. Schinka and W. F. Velicer (eds.) Handbook of Psychology: vol.2 Research Methods in Psychology. Wiley. p143-164.
服部環 (2003). 共通因子数の決定とそれを援助するためのコンピュータ・プログラムの開発. 応用心理学研究, 28, 135-144.
Horn, J. L. (1965). A rationale and test of the number of factors in factor analysis. Psychometrika, 30, 179-185.
Hu, L. T., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling, 6, 1-55.
Marsh, H. W., Hau, K.-T., and Wen, Z.(2004). In search of golden rules: Comment on hypothesis-testing approaches to setting cutoff values for fit indexes and dangers in overgeneralizing Hu and Bentler's (1999) findings. Structural Equation Modeling, 11, 320-341.
Nasser, F., and Wisenbaker, J. (2003). A Monte Carl study investigating the impact of item parceling on measures of fit in confirmatory factor analysis. Educational and Psychological Measurement, 63, 729-757.
Thurstone, L. L. and Thurstone, T. G. (1941). Factorial studies of intelligence. University of Chicago Press. (Psychometric monograph ; no. 2).
Velicer, W. F. (1976). Determining the number of components from the matrix of partial correlations. Psychometrika, 41, 321-327.
Velicer, W.F., Eaton, C.A., & Fava, J.L. (2000). Determining the number of components: A review and evaluation of alternative procedures. In Goffin, R. D., & Helmes, E. (Eds.), Problems and Solutions in Human Assessment: A Festschrift to Douglas Jackson at Seventy. p41-71, Kluwer Academic Publishers.
Zwick, W. R. and Velicer, W. F.(1986).Comparison of five rules for determining the number of components to retain. Psychological Bulletin, 99, 432-442.