SPSS ときど記(201~210)
SPSSを使っていてトラぶったところや変な出力や裏技表技の便利な使い方を中心に書き留めてみる。何回話題があるかわからですが,時々書きます。(Keizo Hori)
最終更新日:
(2004/12/11から)
(191)~(200) ときど記(メニュー)へ
(210)~(220)
- SPSS ときど記(210) 2005/ 3/ 3 AMOS 相関行列データの取り扱い
- SPSS ときど記(209) 2005/ 2/25 AMOS 適合度指標の読み取り
- SPSS ときど記(208) 2005/ 2/21 DATA matrix data と因子分析,重回帰分析,AMOS
- SPSS ときど記(207) 2005/ 2/12 MANOVA MANOVAで正準相関分析
- SPSS ときど記(206) 2005/ 1/26 行列言語 printのtitleを変数指定できるか?
- SPSS ときど記(205) 2005/ 1/19 macro ガットマン尺度マクロ
- SPSS ときど記(204) 2004/12/27 SPSSv13J プロテクトのバージョンアップ2
- SPSS ときど記(203) 2004/12/23 変数名 日本語の変数名
- SPSS ときど記(202) 2004/12/21 BASE tabコードの認識
- SPSS ときど記(201) 2004/12/11 SPSSv13 プロテクトのバージョンアップ
AMOS 相関行列データの取り扱い
(1)分散共分散行列のデータは
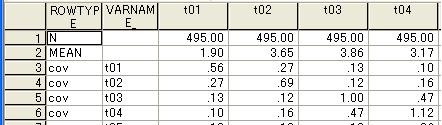
の形である。
(2)相関行列データは
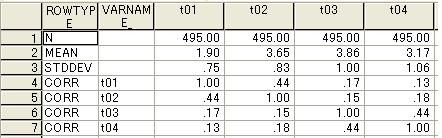 の形である。
の形である。
このデータをamosで分析すると(1)を分析したときと同じになる。
(3)ところで(2)からSTDDEV の行を削除すると次のメッセージがでる。
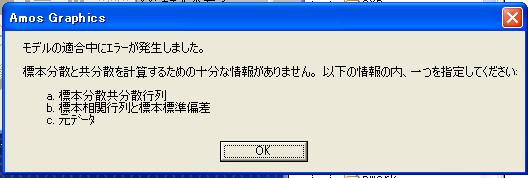
つまり正しく相関行列と認識している。
あ,MEAN は必須要素じゃなかったのね。
ということで,次ののエラーメッセージは ROWTYPE_に許容する語にCORR が抜けていることになる。
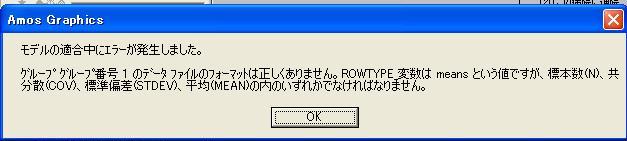
EXCELでAmos用データファイルを作成するときは,(1)(2)のように変数名を含めてデータを入れる。
メニューへ トップへ (211)へ
AMOS 適合度指標の読み取り
適合度指標を読み取る基準はいろいろある。そのような値は言わないようにしている研究者もいる。
Schermelleh-Engel, K., Moosbrugger, H., & Mu"ller, H. (2003). Evaluating the fit of structural equation models: Test of significance and descriptive goodness-of-fit measures. Methods of Psychological Research -
Online, 8(2), 23-74.
http://www.mpr-online.de/issue20/art2/mpr130_13.pdf
に読み方が載っているのでこれを紹介しよう。もちろんこれが絶対ではないので注意。
| モデル評価の経験則 |
| | | | | |
| Fit Measure | | Good Fit | | Acceptable Fit | |
| χ2 | | 0 ≦ χ2 ≦ 2df | | 2df < χ2 ≦ 3df | |
| p value | | .05 < p ≦ 1.00 | | .01 ≦ p ≦ .05 | |
| χ2/df | | 0 ≦ χ2/df ≦ 2 | | 2 < χ2/df ≦ 3 | |
| RMSEA | | 0 ≦ RMSEA ≦ .05 | | .05 < RMSEA ≦ .08 | |
| p value for test of close fit | | | | | |
| (RMSEA < .05) | | .10 < p ≦ 1.00 | | .05 ≦ p ≦ .10 | |
| Confidence interval (CI ), | | close to RMSEA | | close to RMSEA | |
| | left boundary of CI = .00 | | | |
| SRMR | | 0 ≦ SRMR ≦ .05 | | .05 < SRMR ≦ .10 | |
| NFI | | .95 ≦ NFI ≦ 1.00 | | .90 ≦ NFI < .95 | |
| NNFI | | .97 ≦ NNFI ≦ 1.00 | | .95 ≦ NNFI < .97 | |
| CFI | | .97 ≦ CFI ≦ 1.00 | | .95 ≦ CFI < .97 | |
| GFI | | .95 ≦ GFI ≦ 1.00 | | .90 ≦ GFI < .95 | |
| AGFI | | .90 ≦ AGFI ≦ 1.00, | | .85 ≦ AGFI <.90, | |
| | close to GFI | | close to GFI | |
| AIC | 比較モデル中最小の AIC |
| CAIC | 比較モデル中最小のCAIC |
| ECVI | 比較モデル中最小の ECVI |
| | | | | |
メニューへ トップへ (210)へ
DATA matrix data と因子分析,重回帰分析,AMOS
データが相関行列・共分散行列である場合の各種統計命令の処理の仕方が少し違っている。
ROWTYPE_ に入る変数名に MEAN, STDDEV ,N などがある。大文字でも小文字でもかまわない。
SPSSではSTDDEV は STDEV でも許す。
AMOSのエラーメッセージからするとSTDEV のほうが標準である。
相関行列の場合のデータ例 平均,標準偏差がわからないのでそれぞれ,0,1を入れている。これはAmosは共分散行列の処理が求められるためのもの。因子分析の場合はmean, stddevの指定はいらない。
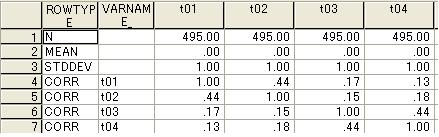
共分散行列の場合 この例は相関行列を共分散行列として扱うようにしたもので,平均を0とおいている。
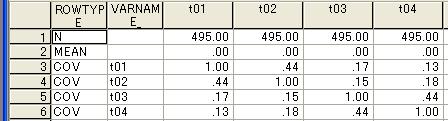
SPSSの重回帰分析において COV を許さない。
許していいはずなのに一貫性がない処理である。
因子分析でN がないと処理してくれないのもちょっと困る。Nが必要なのはML でしょ。
AMOSの場合,共分散行列が前提であるが,corrでもstddev, mean, nが指定してあれば処理する。
警告メッセージの仕方も因子分析と重回帰分析では異なる。同じMEANに対してMEANS という間違ったものを入れると,次のように因子分析では具体的指摘があるが,重回帰分析では具体的な指摘にはならない。Amosは因子分析と同タイプの指摘の仕方をする。
因子分析
警告
MEANS invalid for CORR rowype var ...
このコマンドは実行されません。
|
重回帰分析
警告
ROWTYPE 変数に行列入力に対して無効な値があります。
このコマンドは実行されません。
|
Amos 5.0
メニューへ トップへ (209)へ
MANOVA MANOVAで正準相関分析
MANOVAで正準相関分析ができるらしい。
manova read write with math science
/discrim.
という形でWITH を使用する。
詳しくは,
http://www.ats.ucla.edu/stat/spss/whatstat/whatstat.htm#cancor
正準相関分析のマクロをSPSSは供給しているのでできないのかと思っていた。
メニューへ トップへ (209)へ
行列言語 printのtitleを変数指定できるか?
ガットマン尺度マクロを作成したときmatrix 言語の中のprint命令においてtitleを変数名にしたかった.
しかし,nx に変数名が入っているとして,prinx a/title nx. とするとtitleはnx になるだけでnxに割り当てられた中身を表示することができない.
そこで print命令を2つ使ってタイトルを付けることにした.最初のprint 命令はタイトル用である.
print x/title =" "/cnames=nx.
という感じでnx を表示する.ところで,変数名をタイトルに付けたいのでnx はこの分析に使っている変数名がベクトルになって収まっている.nx(3)として変数名をだすことができるかというと,残念ながらできない.
そうすとと
compute xname=nx(3).
print x/title= " "/cnames=xname.
print y/title= " ".
というようになる.title= " "としているのはtitle指定がないとprint文のxという変数名が出力されるためである.実際には変数名をループさせていくので
loop i=1 to ncol(d).
compute x={0;1;d(:,i)}.
compute y={0;1;c(:,i)}.
compute x=design(x).
compute y=design(y).
compute x=x(3:nrow(x),:).
compute y=y(3:nrow(y),:).
compute z=t(y)*x.
compute z2=csum(z).
compute z={z;z2}.
compute z2=rsum(z).
compute z={z,z2}.
compute nxi=nx(i).
print {d33(i), z(3,2)/z(3,3),(z(1,1)+z(2,2))/z(3,3)}/title=" "/clabels="oreder" "true" "conting"
/rname=nxi/format f8.3.
compute rn={"0 (est)"; "1 (est)";"total"}.
print z/title=" "/rname=rn /clabels="0 (data)" "1 (data)" "total".
end loop.
という形になる.太字がここで関係しているところ.
もう一つマクロ変数を使う手がありそうであるが試していない.行列言語とマクロ言語はループの中でうまくいかないことがある.
メニューへ トップへ (207)へ
macro ガットマン尺度マクロ
ガットマン尺度マクロを作成した.手抜きバージョンでタイの項目があるとちょっと困る.ガットマン再現性係数などを知りたい向きには使えるだろう.
http://www.ec.kagawa-u.ac.jp/~hori/spss/spss.html#guttmacro
メニューへ トップへ (206)へ
SPSSv13J プロテクトのバージョンアップ2
SPSS13jが来ました.プロテクトは2台までインストールできるようになっている.
メニューへ トップへ (205)へ
変数名 日本語の変数名
最近,学生の卒論で情報処理センターにあるSPSSを使ったりする.11.0である.研究室で使っているのは12.01Jである.学生が卒論で変数名に漢字等の2バイト文字を使っている.そのSPSSファイルを研究室で読むと変数名が変わっている.
12で漢字等の2バイト文字を入れようとすると拒否される.12では変数名に2バイト文字が使えない.半角カタカナは使うことができる.このことアナウンスされていたかな.
しかも,excel からだと変数名が転用できないとき,value labelsになるのにそのようなこともしない.なんと不便なことになったの.変数名の字数を増やすという愚かなことをするなら2バイト文字を使えるままにするほうが便利なんじゃない.
さらにチェックを入れたところ他のパソコンでは12でもちゃんと2バイト文字が表示された.なんかの設定なのだろうか?よくわからない.windows98 と xp の違い?
メニューへ トップへ (204)へ
BASE tabコードの認識
spss 12.0で読むシンタックス窓のbegin data .. end data.で囲まれたデータをspss 11.5 で読むとエラーが生じる.なぜなんだろうと見たところ次のことだった.
spss 12ではタブコードをデータの区切りと認識してくれるが,spss11.5では区切りと認識しなくて連続して読んでしまう.この現象は11.0でもある.
メニューへ トップへ (203)へ
SPSSv13 プロテクトのバージョンアップ
spssx-l の情報によると,SPSS v13 はプロテクトの仕様をMS-Offece などと同じように一つのパソコンにしかインストールできないようにしているようである.
すでに契約では1台にしかインストールできないことになっていた.この仕様にするとパソコンを買い換えた時の面倒が格段に増える.一つのソフトだけならまだいいのだが,よってたかってこの仕様になるとパソコンを変えるのが億劫になる.
メニューへ トップへ (202)へ
堀 啓造ホームページへ