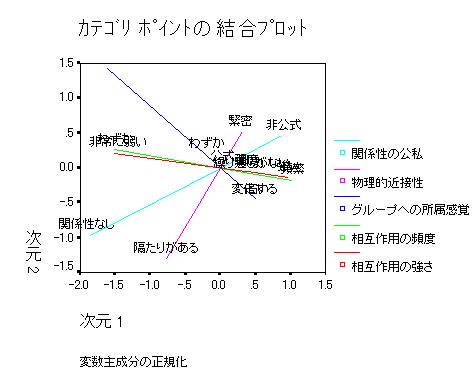
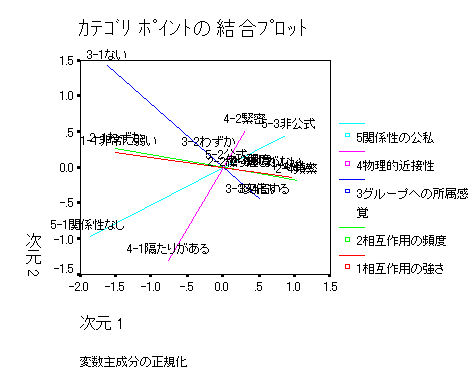
被験者間効果の検定
従属変数: 認知閾
| ソース |
タイプ III 平方和 |
自由度 |
平均平方 |
F 値 |
有意確率 |
|---|
| 切片 |
仮説
| 64325.641 |
1 |
64325.641 |
28.979 |
.012 |
|---|
| 誤差
| 6784.972 |
3.057 |
2219.724(a) |
|
|
| 文字の大 |
仮説
| 8906.641 |
1 |
8906.641 |
42.250 |
.004 |
|---|
| 誤差
| 763.923 |
3.624 |
210.807(b) |
|
|
| 熟知度 |
仮説
| 1859.766 |
1 |
1859.766 |
10.066 |
.037 |
|---|
| 誤差
| 686.265 |
3.714 |
184.766(c) |
|
|
| 文字の大 * 熟知度 |
仮説
| 206.641 |
1 |
206.641 |
2.741 |
.163 |
|---|
| 誤差
| 349.675 |
4.638 |
75.391(d) |
|
|
| 文字の大 * 熟知度 * 刺激語 |
仮説
| 601.563 |
12 |
50.130 |
1.711 |
.105 |
|---|
| 誤差
| 1054.688 |
36 |
29.297(e) |
|
|
| 被験者 |
仮説
| 6596.672 |
3 |
2198.891 |
7.346 |
.041 |
|---|
| 誤差
| 1220.402 |
4.077 |
299.349(f) |
|
|
| 文字の大 * 被験者 |
仮説
| 569.922 |
3 |
189.974 |
3.482 |
.166 |
|---|
| 誤差
| 163.672 |
3 |
54.557(g) |
|
|
| 熟知度 * 被験者 |
仮説
| 491.797 |
3 |
163.932 |
3.005 |
.195 |
|---|
| 誤差
| 163.672 |
3 |
54.557(g) |
|
|
| 文字の大 * 熟知度 * 被験者 |
仮説
| 163.672 |
3 |
54.557 |
1.862 |
.153 |
|---|
| 誤差
| 1054.688 |
36 |
29.297(e) |
|
|
| a MS(文字の大 * 熟知度 * 刺激語) + MS(被験者) - 1.000 MS(誤差) |
| b 1.000 MS(文字の大 * 熟知度 * 刺激語) + MS(文字の大 * 被験者) - 1.000 MS(誤差) |
| c MS(文字の大 * 熟知度 * 刺激語) + 1.000 MS(熟知度 * 被験者) - 1.000 MS(誤差) |
| d 1.000 MS(文字の大 * 熟知度 * 刺激語) + 1.000 MS(文字の大 * 熟知度 * 被験者) - 1.000 MS(誤差) |
| e MS(誤差) |
| f MS(文字の大 * 被験者) + MS(熟知度 * 被験者) - 1.000 MS(文字の大 * 熟知度 * 被験者) |
| g MS(文字の大 * 熟知度 * 被験者)
|